




How to Save Scraped Data in Google Sheets

Scraping web data can be an immensely powerful tool for data analysts, web developers, SEO professionals, and Python enthusiasts alike. But what happens once you extract that data? If you’re spending hours manually pasting it into spreadsheets for analysis, there’s a better way.
This guide will teach you how to automate the process of saving scraped web data directly into Google Sheets using Python. For this example, we’ll scrape book details, such as titles, prices, and availability, from the "Books to Scrape" website—and save it seamlessly to a Google Sheet.
By the end of this tutorial, you’ll not only learn how to scrape data with Python but also how to integrate Google Sheets into your workflow for organized and efficient data analysis.
Prerequisites
Before we get started, here's what you’ll need:
Setting Up Google Cloud
To interact with Google Sheets programmatically, we’ll employ the Google Sheets API. Here’s how to get set up:
- Create a Google Cloud Account: If you don’t already have one, sign up for a free account at Google Cloud.
- Enable Google Sheets API: Navigate to your Google Cloud Console, create a new project, and enable the Google Sheets API.
- Create a Service Account: Under IAM & Admin > Service Accounts, create a new service account for your project. Grant the role Editor and download the service account’s credentials file in JSON format. Check this link or a detailed tutorial.
- Secure Credentials: Save the credentials `.json` file in a safe spot on your system. You’ll need its file path later when authenticating with the Google Sheets API.
If you need help with these steps, check out this tutorial for detailed guidance.
Installing Required Tools
Ensure Python is installed on your computer. Then, install the following Python libraries using `pip`:
requests: For making HTTP requests to the website.bs4: For parsing HTML content (via BeautifulSoup).gspread: For interacting with Google Sheets.
Command to install libraries:
pip install requests beautifulsoup4 gspreadCreating the Google Sheet
Start by creating a Google Sheet to store your scraped data:
1. Create a New Sheet:
Go to Google Sheets and create a new spreadsheet. For this example we will name it `Book Data`.
2. Grant Access to the Sheet: Now is time to grant access to the sheet so we can use it inside the script. There are two ways to do that:
- Using Service Account Email: To locate the service account email, open the JSON key file you downloaded. Look for the
client_emailfield within the file. After copying the service account email, open the Google Sheet you created, click the "Share" button, and add the email. Make sure to set the permissions to "Editor." - Making the Sheet Public: Making the Google Sheet public removes the need to authenticate it with a service account email. If your script needs to edit the sheet, you’ll need to give it "editor" permissions. For reading data only, "viewer" permissions are enough. In this tutorial, we’ll be writing book data to the sheet, so be sure to set the permissions to "editor."
Python Code for Scraping
For this tutorial, we’ll be using the Books to Scrape website as our data source. This website is a perfect playground for practicing web scraping.
Here’s what we’ll scrape from the first page:
- Title: The book’s title.
- Price: The cost of the book.
- Availability: Whether the book is in stock.
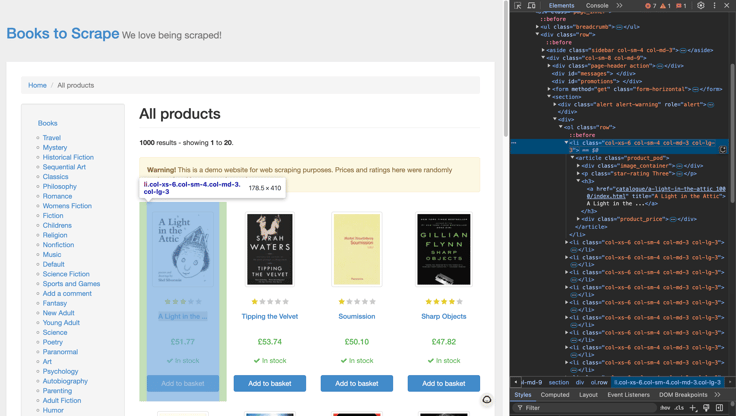
We’ll start by using the requests library to send an HTTP request and get the website’s HTML content. Next, we’ll use the BeautifulSoup library to parse the HTML and extract the needed data with CSS selectors. Finally, we’ll save the extracted data as a list of dictionaries, with each dictionary containing a book’s title, price, and availability.
from typing import List
import gspread
import requests
from bs4 import BeautifulSoup
def extract_book_data() -> List[dict]:
book_data = []
url = "http://books.toscrape.com/"
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
books = soup.find_all('li', class_='col-xs-6 col-sm-4 col-md-3 col-lg-3')
for book in books:
title = book.find('h3').find('a')['title']
price = book.find('p', class_='price_color').text
availability = book.find('p', class_='instock availability').text.strip()
book_data.append({
'title': title,
'price': price,
'availability': availability
})
return book_dataUsing Gspread to Interact with Google Sheets
We will define the save_books_to_google_sheet function, which is responsible for taking a list of books and pushing it to a Google Sheet.
This function takes three arguments:
- json_key_path: The path to the service account key JSON file. This file contains the credentials necessary to authenticate with the Google Sheets API, as explained in the section above on how to download the file.
- spreadsheet_url:The URL of the Google Spreadsheet. Remember, the spreadsheet should either be public or explicitly shared with the service account email. If the service account email does not have access, the script will not be able to update the sheet.
- books_data:The list of dictionaries containing book details. Each dictionary should have the keys
title,price, andavailabilityto represent the book’s title, price, and availability status, respectively.
The function will authenticate with Google Sheets using the gspread.service_account()
Here is the code that implements this functionality:
def save_books_to_google_sheet(json_key_path, spreadsheet_url, books_data):
"""
Save book data into a Google Sheet.
Args:
json_key_path (str): Path to the service account JSON key file.
spreadsheet_url (str): URL of the Google Spreadsheet.
books_data (list of dict): List of dictionaries containing book data (title, price, availability).
Returns:
None
"""
try:
# Authenticate using the service account key file
client = gspread.service_account(filename=json_key_path)
# Open the Google Sheet by URL
sheet = client.open_by_url(spreadsheet_url).sheet1
# Write column headers (optional)
sheet.update("A1", [["Title", "Price", "Availability"]])
# Write book data to the sheet
for index, book in enumerate(books_data, start=2): # Start writing from row 2
sheet.update(f"A{index}", [[book["title"], book["price"], book["availability"]]])
print("Data successfully written to Google Sheet!")
except Exception as e:
print(f"An error occurred: {e}")
# Example usage
if __name__ == "__main__":
# Example inputs
json_key_path = "service_account.json" # Path to the JSON key file
spreadsheet_url = "https://docs.google.com/spreadsheets/d/your_spreadsheet_id_here" # Replace with your spreadsheet URL
books_data = [
{"title": "A Light in the Attic", "price": "£51.77", "availability": "In stock"},
{"title": "Tipping the Velvet", "price": "£53.74", "availability": "In stock"},
{"title": "Soumission", "price": "£50.10", "availability": "In stock"}
]
# Call the function
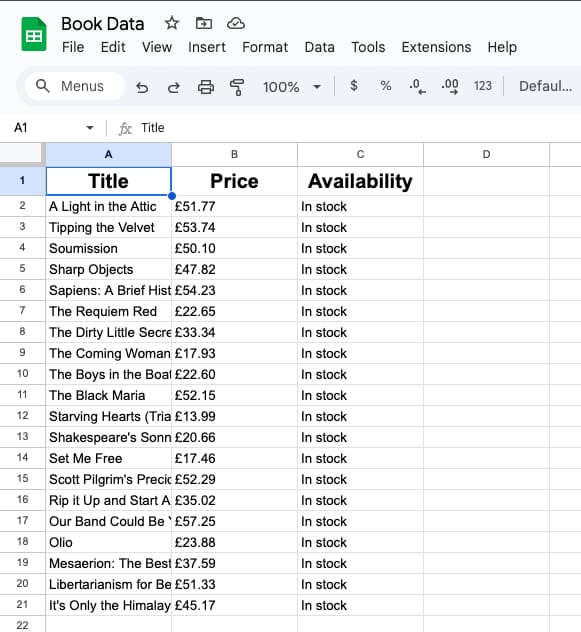
save_books_to_google_sheet(json_key_path, spreadsheet_url, books_data)This is how the data on the google sheet looks like after we run this script
Putting It All Together
Congratulations! You’ve just automated the cumbersome task of saving scraped web data into a Google Sheet. Here’s a recap of what we accomplished:
- Set up Google Sheets API and installed the necessary libraries.
- Scraped book data (titles, prices, availability) from “Books to Scrape” using `requests` and `BeautifulSoup`.
- Used
gspreadand Google Sheets API to export the data into a spreadsheet.
This workflow is perfect for data analysts, developers, and SEO professionals who need scraped data stored neatly and efficiently. Whether you’re monitoring e-commerce websites or collating marketing insights, the possibilities are endless.