





You can automatically extract large amounts of data from websites using web scraping and save it in a database or a file. The scraped data can be mostly stored in a spreadsheet or tabular format. Web scraping is also called web data extraction web harvesting. It is needed because manual scraping is a tedious task
Table of Contents
- Why Is There A Need For Web Scraping?
- Web Scraping In Python
- Import Libraries
- Add Header and URL
- BeautifulSoup Object
- Iterating Through Rows
- Create a Dataframe
- Proxies For Web Scraping Using Python
- Import Libraries
- Define a Function
- Use a For Loop
- List of Working Proxies
- Request Session
- Make a Request
- Why are Proxies Important For Web Scraping?
- Conclusion on this Python For Web Scraping Tutorial
You can automatically extract large amounts of data from websites using web scraping and save it in a database or a file. The scraped data can be mostly stored in a spreadsheet or tabular format. Web scraping is also called web data extraction web harvesting. It is needed because manual scraping is a tedious task that may take hours or even days to complete. So, you need to automate the process and extract the data from websites within a fraction of time.
You can use web scraping software to automatically load, crawl, and extract data from a website’s multiple pages based on your needs and requirements. In short, you can get your desired data from websites with the click of a button. In the modern world, businesses need to analyze the data and perform intelligent actions. But sometimes, getting data from websites is difficult when the website owners employ techniques such as IP bans and CAPTCHAs. You can use proxy servers or VPNs to overcome this problem as they help you scrape data from the web anonymously.
Why Is There A Need For Web Scraping?
Businesses worldwide scrape data from the web to gain useful insights by storing it in a usable format. Some of the pros of web scraping in various industries are given below.
- Web scraping collects train and test datasets for machine learning projects.
- In eCommerce, web scraping is used to monitor competitors’ prices.
- Web scraping is used in Real Estate to get property and owner/agent details.
- In Marketing, web scraping is used for building phone and email lists for cold outreach.

Below are the main reasons for scraping data from the web.
Achieving automation – You can extract data from websites by using robust web scrapers. This way, you can save time from mundane data collection tasks. You can collect data at greater volume than a single human can ever hope to achieve with web scraping. Further, you can also create sophisticated web bots for automating online activities either using a programming language such as Python, Javascript or using a web scraping tool.
Rich and Unique Datasets – You can get a rich amount of images, videos, text, and numerical data from the Internet. You can also find relevant websites and make your custom dataset for analysis, depending on your objective. For instance, you are interested in understanding the UK sports market in depth. You can set up web scrapers to gather the video content or football statistics information for you.
Effective Data Management – You do not need to copy and paste data from the Internet as you can accurately collect data from various websites with web scraping. In this way, your company and employees can spend more time on creative work by effectively storing data with automatic software and programs.
Business Intelligence and Insights – Web scraping from the Internet allows you to do the following:
- Monitoring the competitors’ marketing activity
- Searching for competitors’ prices
- Building a bigger picture of your market
Further, businesses can achieve better decision-making by downloading, cleaning, and analyzing data at a significant volume.
Speed – Web scraping extracts data from websites with great speed. It allows you to scrape data in hours instead of days. But some projects may take time depending on their complexity and the resources and tools that we use to accomplish them.
Data Accuracy – Manual extraction of data from websites involves human error, leading to serious problems. Therefore, accurate data extraction is crucial for any information, which can be accomplished with web scraping.
Web Scraping In Python
Suppose you have to extract data from this website. You will have to install the two Python modules namely requests and BeautifulSoup.

Import Libraries
You can install these modules by using the following command.
!pip install requests
!pip install BeautifulSoupYou can import these modules as:
from bs4 import BeautifulSoup
import requestsYou can click on the Inspect button on the top left corner of the website to highlight the elements you wish to extract. In our case, we want to extract the table data of this site as shown below.
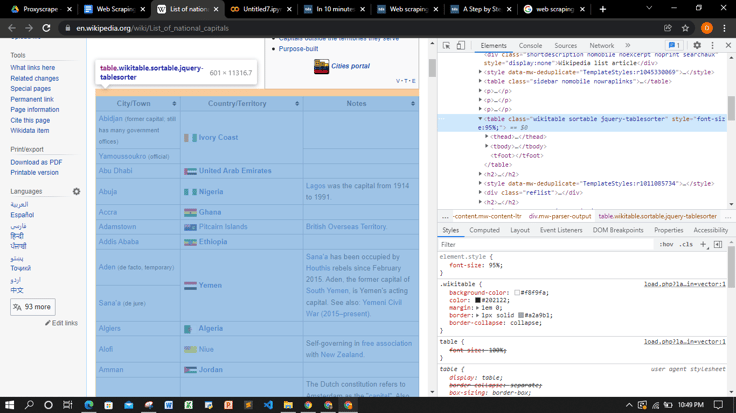
Add Header and URL
You have to add the header and URL to your requests. The header can take off your request so that it looks like it comes from a legitimate browser.
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36'}
url = "https://en.wikipedia.org/wiki/List_of_national_capitals"You can use the requests.get() function for sending a GET request to the specified URL.
r = requests.get(url, headers=headers)BeautifulSoup Object
You have to initialize a BeautifulSoup object and mention its parameters. Then, you have to extract all rows of the table. You can get all the table elements by using find_all() method as shown in the code below.
soup = BeautifulSoup(r.content, "html.parser")
table = soup.find_all('table')[1]
rows = table.find_all('tr')
row_list = list()Iterating Through Rows
You can use a for loop to iterate through all rows in the table as shown in the code below.
for tr in rows:
td = tr.find_all('td')
row = [i.text for i in td]
row_list.append(row)Create a Dataframe
You can visualize the extracted data clearly if you create a Pandas dataframe and export your data into a .csv file. For creating a dataframe, you have to import Pandas, as shown below.
import pandas as pdNow, you can convert your soup object into a dataframe that will contain the following table rows.
- City
- Country
- Notes
You can convert your dataframe into a csv format and print your dataframe as shown below.
df_bs = pd.DataFrame(row_list,columns=['City','Country','Notes'])
df_bs.set_index('Country',inplace=True)
df_bs.to_csv('beautifulsoup.csv')
print(df_bs)You will get the below output.

Proxies For Web Scraping Using Python
A proxy acts as an intermediary or a middleman between a client and a server. It hides your real IP address and bypasses filters and censorship. You can grab a free list of proxies by just using a function in Python, as shown in the steps below.

Import Libraries
You have to import the below modules in Python.
from bs4 import BeautifulSoup
import requests
import randomDefine a Function
You can define a get_free_proxies() function in which you have to mention the URL of the free proxy list. Then, you have to create a BeautifulSoup object and get the HTTP response by using requests.get() function.
def get_free_proxies():
url = "https://free-proxy-list.net/"
soup = bs(requests.get(url).content, "html.parser")
proxies = []Use a For Loop
You can use the find_all() method in the for loop to iterate through all table rows as shown below.
for row in soup.find("table", attrs={"id": "proxylisttable"}).find_all("tr")[1:]:
tds = row.find_all("td")
try:
ip = tds[0].text.strip()
port = tds[1].text.strip()
host = f"{ip}:{port}"
proxies.append(host)
except IndexError:
continue
return proxiesList of Working Proxies
You can mention the list of some working proxies like the one we mentioned below.
proxies = [
'167.172.248.53:3128',
'194.226.34.132:5555',
'203.202.245.62:80',
'141.0.70.211:8080',
'118.69.50.155:80',
'201.55.164.177:3128',
'51.15.166.107:3128',
'91.205.218.64:80',
'128.199.237.57:8080',
]Request Session
You have to create a function get_session() that will accept a list of proxies. It also creates a requests session that randomly selects any of the proxies passed as shown in the code below.
def get_session(proxies):
session = requests.Session()
proxy = random.choice(proxies)
session.proxies = {"http": proxy, "https": proxy}
return sessionMake a Request
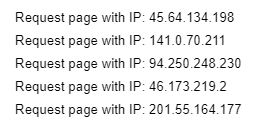
You can use a for loop to make a request to a website and get an IP address in return.
for i in range(5):
s = get_session(proxies)
try:
print("Request page with IP:", s.get("http://icanhazip.com", timeout=1.5).text.strip())
except Exception as e:
continueYou can get the following output.
Why are Proxies Important For Web Scraping?
Businesses can extract valuable data to make data-driven decisions and offer data-powered services with web scraping. Proxies are important for web scraping because of the following reasons.
- With proxies, you can make requests from a particular geographical region and see the specific content that the website displays for that given location. This feature of proxies is beneficial when you are scraping product data from online retailers.
- Proxies allow you to make a higher volume of requests to a target website without getting blocked or banned.
- Proxies allow you to crawl data from websites more reliably and efficiently.
- With proxies, you can make unlimited concurrent sessions to the same or different websites without the fear of getting banned.
- A proxy hides your machine’s IP address from the target website, thus providing additional security to your device.
- Businesses use proxies to monitor the competitors’ prices and product features to improve their services and products.

Conclusion on this Python For Web Scraping Tutorial
So far, we discussed that web scraping helps us extract data from websites in an automated manner. You can convert the data into a usable format like a .csv file. Businesses use web scraping to check the competitors’ prices and product features. Web scraping is of great use if you use proxies as they keep your identity anonymous by hiding your original IP address from the target website. With proxies, you can send multiple requests to the website without the fear of getting blocked or banned.