




What is data parsing?

Data Parsing is a term that you often come across when you work with large quantities of data, especially for those who scrape data from the web as well as software engineers. However, data parsing is a topic that needs to be discussed in greater depth. For instance, what exactly is data parsing, and how
Data Parsing is a term that you often come across when you work with large quantities of data, especially for those who scrape data from the web as well as software engineers. However, data parsing is a topic that needs to be discussed in greater depth. For instance, what exactly is data parsing, and how do you implement it in the real world.
This article will answer all the above questions and provide an overview of the significant terminologies associated with data parsing.
What does parsing mean?
When you extract extensive quantities of data from web scraping, they are in HTML format. Unfortunately, this is not in a readable format for any non-programmer. So you have to do further work on the data to make them in a human-readable format making it convenient for analysis by data scientists. It is the parser that carries out most of this heavy lifting in parsing.
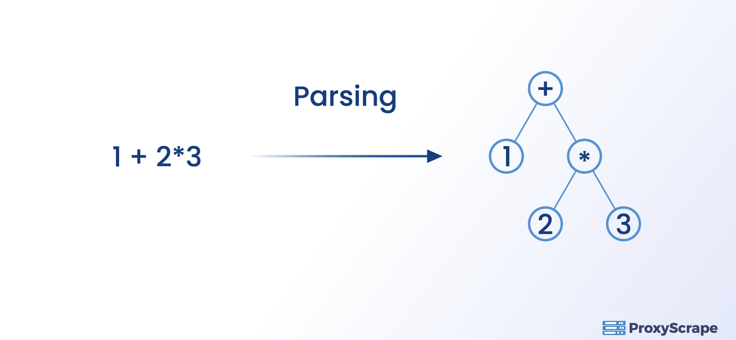
What does a data parser do?
A Parser will convert data in one format to data in another form. For example, the parser will convert the HTML data that you obtained through scraping to JSON, CSV, and even a table so that it is in a format that you can read and analyze. It is also worth mentioning that the parser is not tied to any particular data format.
The parser does not parse every HTML string because a good parser will distinguish the required data in HTML tags from the rest.
Different technologies that use parser
As mentioned in the previous section, since the parser is not tied to one specific technology, it is exceptionally flexible by nature. Therefore a wide variety of technologies use them:
Scripting Languages- these are the languages that do not need a compiler for execution as they run based on a series of commands within a file. Typical examples are PHP, Python, and JavaScript.
Java and other programming languages- High-level programming languages such as Java use a compiler to convert the source code to Assembly language. The parser is a significant component of these compilers which creates an internal representation of the source code.
HTML and XML- with the case of HTML the parser extracts the text in HTML tags such as title,headings,paragraphs etc. Whereas an XML parser is a library that facilitates the reading and manipulation of XML documents.
SQL and Database languages- The SQL parser, for instance, parses an SQL query and generates the fields defined in the SQL query.
Modeling languages- parser in modeling languages allows developers, analysts, and stakeholders to understand the structure of the system that’s being modeled.
Interactive data languages- are used in the interactive processing of large quantities of data, including space science and solar physics.
Why do you need data parsing?
The primary reason for the need for parsing is that various entities need data in different formats. Parsing thus allows transforming data so that a human or, in some instances, the software can understand. One prominent example of the latter is computer programs. First, humans write them in a format that they can understand with a high-level language analogous to a natural language like English that we use daily. Then the computers translate them into a form up to machine-level code that the computers comprehend.
Parsing is also necessary for situations where communication is needed between two different software—for example, serializing and deserializing a class.
The Parsing terminology and the structure of the parser
Up to this juncture, you know the fundamental concepts of data parsing. Now it’s time to explore the significant concepts associated with data parsing and how the parser works.
Terminology

Regular expressions
Regular expressions are a series of characters that define a particular pattern. They are most commonly used by high-level and scripting languages to validate an email address or date of birth. Although they’re considered unsuitable for data parsing, they can still be used for parsing simple input. This misconception arises because certain programmers use regular expressions for every parsing task, even when they are not supposed to be used. In such circumstances, the result is a series of regular expressions that are hacked together.
You can use regular expressions to parse some simple programming languages, also known as regular languages. However, this does not include HTML, which you can consider as a simple language. This is due to the fact that inside HTML tags, you will encounter any number of arbitrary tags. Also, according to its grammar, it has recursive and nested elements that you can not classify as regular language. Therefore you can not parse them no matter how clever you are.
Grammars
Grammar is a set of rules that describes a language syntactically. Thus, it applies to only the syntax and not the semantics of a language. In other words, the grammar applies to the structure of a language and not its meaning. Let’s consider the below example:
HI: “HI”
NAME: [a-zA-z] +
Greeting: HI NAME
Two of the possible outputs for the above piece of code can be “HI SARA” or “HI Coding”. As far as the structure of the language is concerned, both of them are correct. However, in the second output, since “Coding” is not a person’s name, it’s incorrect semantically.
Anatomy of Grammar
We can look at the anatomy of grammar with the commonly used forms, such as the Backus-Naur Form (BNF). This form has its variants which is the Extended Backus-Naur Form, and it indicates repetition. Another variant of BNF is the Augmented Backus-Naur Form. It is used when describing bidirectional communications protocols.
When you’re using a typical rule in Backus-Naur Form, it looks like this:
<symbol> : : _expression_
The <symbol> is nonterminal, which means you can replace it with elements on the right, _expression_. The _expression_ could contain terminal symbols as well as nonterminal symbols.
Now you might be asking what terminal symbols are? Well, they’re the ones that do not appear as a symbol in any component of grammar. A typical example of a terminal symbol is a string of characters such as “Program.”
Since the rule such as the above technically defines the transformation between the nonterminal and group of nonterminal and terminal on the right it can be called the production rule.
Type of Grammars
There are two types of grammars, and they are Regular grammar and context-free grammars. Regular grammar are used to define a common language. There is also a more recent type of grammar known as Parsing Expression Grammar (PEG), representing context-free languages and they’re also powerful as context-free grammars. Anyhow the difference between the two types depends on the notation and how the rules are being implemented.
An easier way which you could differentiate between two grammars are the _expression_, or the right side of the rule could be in the form of :
- An empty string
- A single terminal symbol
- A single terminal symbol is followed by a non-terminal symbol.
In reality, this is easier said than done because a particular tool could allow more terminal symbols in one definition. Then it could transform the expression into a correct series of expressions that belongs to either of the above cases.
So even a vulgar expression that you write will be transformed into proper form, although it’s not compatible with a natural language.
Components of a parser

As the parser is responsible for analyzing a string of symbols in a programming language conforming to the grammar rules that we just discussed, we can break down the parser’s functionality into a two-step process. Typically the parser is instructed to programmatically read, analyze and transform the unstructured data to a structured format.
The two major components that make up a parser are lexical analysis and syntactical analysis. In addition, some parsers also implement a semantic analysis component that takes the structured data and filters them as: positive or negative, complete or incomplete. Although you may assume that this process further enhances the data analysis process, it’s not always the scenario.
Semantic analysis is not built into most parsers due to the more favored practices of human semantic analysis. Therefore the semantic analysis should be an additional step, and if you plan to carry it out, it must complement your business goals.
Let’s then discuss the two main processes of the parser.
Lexical Analysis
It is performed by the Lexar, which is also called the scanners or tokenizers, and their role is to transform a sequence of raw unstructured data or characters into tokens. Often this string of characters that enter the parser is in HTML format. Then the parser creates tokens by utilizing lexical units, including keywords, identifiers, and delimiters. Simultaneously the parser ignores the lexically irrelevant data that we touched upon in the introductory section. For example, they include whitespaces and comments inside an HTML document.
After the parser discards the irrelevant tokens during the lexical process, the rest of the parsing process deals with syntactic analysis.
Syntactic Analysis
This phase of data parsing consists of constructing a parse tree. This implies that after the parser creates the tokens, it arranges them into a tree. During this process, the irrelevant tokens are also captured into the nesting structure of the tree itself. Irrelevant tokens include parenthesis, semicolons, and curly brackets.
In order for you to understand this better, let’s illustrate it with a simple math equation: (a*2)+4
the Lexer of the parser will then break them down into tokens as follows:
( => Parenthesis
a => Value
* => Multiply
2 => Value
)=> Parenthesis
+ => Plus
4 => Value
Thereafter the parse tree would be constructed as below.:
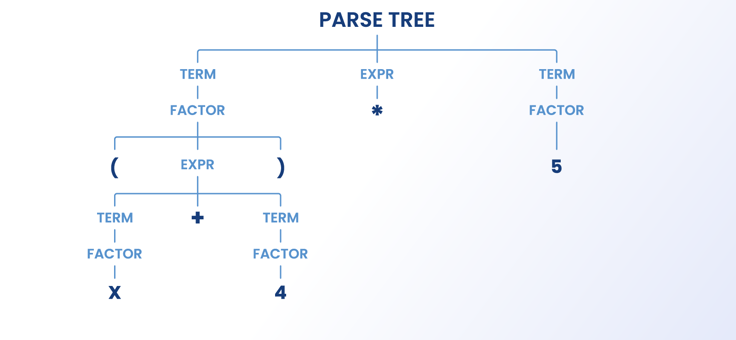
When the parser extracts data from HTML elements, it will follow the same principle.
In-house parser or outsource parser?
Now you have gained an understanding of the fundamental aspects of a parser. Now is the time for the exciting aspect of whether to build your parser or to outsource one. First, let’s look into the pros and cons of each method.

Pros of an in-house parser
There are numerous benefits to you when you build an in-house parser. One of the key benefits includes you having more control over the specifications. In addition, since the parsers aren’t restricted to any one data format, you have the luxury of making it customizable to meet different data formats.
Some of the other significant benefits include savings on costs and having control over updating and maintaining the in-built parser.
Cons of in-house parser
The in-house parser is not without its pitfalls. One of the significant drawbacks is that it would consume plenty of your valuable time when you have substantial control over its maintenance, updates, and testing. The other drawback would be whether you can buy and build a powerful server to parse all your data faster than you require. Finally, you would need to train all your in-house staff to build the parser and provide training on it.
Pros of an outsource parser
When you outsource a parser, it will save money that you spend on human resources as the purchasing company will provide you with all the tasks, including servers and the parser. In addition, you will be least likely to confront significant errors as the company that built it is more likely to test all the scenarios before they release it to the market.
If any error arises, there would be technical support from the company you purchased the parser from. You will also save ample time as the decision-making on building the best parser will come from outsourcing.
Cons of an outsource parser
Although outsourcing has numerous benefits, there are downsides to it as well. Major drawbacks come in the form of customizability and cost. Since the parsing company has created the complete functionality, it would incur more cost. In addition, your full control of the parser functionality would be limited.
Conclusion
In this lengthy article, you have learned about how the parser works, and data parsing process in general, and its fundamentals. Data parsing is a long and complicated process. When you get a chance to experience data parsing hands-on, you are now well equipped with a wealth of knowledge on carrying it out effectively.
We hope you will use this knowledge effectively.