




An Introduction To Web Scraping With Node.js (JavaScript)

Are you looking for ways to make use of new technologies? Web extraction or web scraping provides you with a way to collect structured web data in an automated manner. For instance, web scraping is used in the E-commerce world to monitor the pricing of competitors’ services and products. Other use cases of web scraping
Table of Contents
- Why Use Node.js for Web Scraping?
- Web Scraping Using Node.js
- Project Setup
- Set Request
- Make Request
- Use the Data
- The Importance of Using Node.js With Proxies
- Conclusion on Web Scraping Using Node.js
Are you looking for ways to make use of new technologies? Web extraction or web scraping provides you with a way to collect structured web data in an automated manner. For instance, web scraping is used in the E-commerce world to monitor the pricing of competitors’ services and products. Other use cases of web scraping are given below.
- Finding trending data on social media sites
- Collecting data from another website to use on your own website
- Extracting email addresses from websites that publish public emails
- Scraping online stores for product pictures and sales data
You will learn how to do web scraping with Node.js. But first, we look into what Node.js is. It is an open-source server-side platform to develop server-side and networking applications. Its library is very fast in code execution because its applications do not buffer any data. They simply output the data in chunks. Given below are some of the areas where we can use Node.js.
- Data Streaming Applications
- Single Page Applications
- Input/Output Bound Applications
- Data-Intensive Real-Time Applications
Why Use Node.js for Web Scraping?
Following are the reasons to use Node.js for web scraping.
Easy to Learn – Javascript is a popular programming language used by frontend developers. They can quickly learn and use Node.js at the backend as it is a simple Javascript. So, they don’t have to put an extra effort into learning Node.js.
Single Programming Language – You can use Node.js to write server-side applications in Javascript. In short, the Node.js developers use Javascript to write both frontend and backend web applications. They do not need to use any other server-side programming language. Thus, they can easily deploy web applications because almost all web browsers support Javascript.
Scalability – The Node.js developers can easily scale the applications in horizontal and vertical directions. They can add additional nodes to the existing systems to scale the applications horizontally. They can vertically scale the applications by adding extra resources to the single nodes.
High Performance – Node.js uses Google’s V8 Javascript engine to interpret the Javascript code as it compiles it directly into the machine code. Thus, you can effectively implement the code using this engine.
Caching – The developers can also cache single modules using the open-source runtime environment of Node.js. Caching allows the applications to load the web pages faster, so developers don’t have to reuse the codes.

Web Scraping Using Node.js
For web scraping using Node.js, we will be using the following two npm modules.
cheerio – It is a Javascript technology used for extracting data from websites. It helps to select, edit and view DOM elements.
request-promise – It is a simple HTTP client that you can use to make quick and easy HTTP calls.

Project Setup
You have to create a new project folder. Create an index.js file within that folder. Then you have to install the dependencies. For this, open your command line and type the following command.
npm install --save request request-promise cheerioYou have to require the request-promise and cheerio in your index.js file using the below code.
const rp = require('request-promise');
const cheerio = require('cheerio');Set Request
You know that request-promise is a client ‘request’ with Promise support. In other words, it accepts an object as input and returns a promise.
const options = {
uri: `https://www.yourURLhere.com`,
transform: function (body) {
return cheerio.load(body);
}
};In the above code, the options object has to do two things.
- Passing in the URL, you want to scrape
- Loading the returned HTML using cheerio so you can use it.
The uri key in the code is the website you want to scrape.
The transform key loads the returned body into cheerio using request-promise before returning it to us.
Make Request
You can make your request using the code below.
rp(OPTIONS)
.then(function (data) {
// REQUEST SUCCEEDED: DO SOMETHING
})
.catch(function (err) {
// REQUEST FAILED: ERROR OF SOME KIND
});We are passing the options object to request-promise in the above code. We then wait to see if our request succeeds or fails.
Now, we create our own version of the code in which we use arrow functions as shown below.
rp(options)
.then(($) => {
console.log($);
})
.catch((err) => {
console.log(err);
});You have to replace the placeholder uri with the website you want to scrape. You can then open up your console and type the following in the index.js file.
{ [Function: initialize]
fn:
initialize {
constructor: [Circular],
_originalRoot:
{ type: 'root',
name: 'root',
namespace: 'http://www.w3.org/1999/xhtml',
attribs: {},
...This is how you can make your first scrape using Node.js. Here’s the full code we did so far.
const rp = require('request-promise');
const cheerio = require('cheerio');
const options = {
uri: `https://www.google.com`,
transform: function (body) {
return cheerio.load(body);
}
};
rp(options)
.then(($) => {
console.log($);
})
.catch((err) => {
console.log(err);
});Use the Data
You can use cheerio to extract the data you want. The implementation of cheerio’s selector is nearly the same as that of jQuery’s. You can use the selector method for traversing and selecting elements in the document. You can also use it to get and set data. For instance, you want to scrape the following HTML of a website.
<ul id="cities">
<li class="large">Europe</li>
<li id="medium">Turkey</li>
<li class="small">Salem</li>
</ul>We can use ‘#’ to select id’s, ‘.’ to select classes. The elements can be selected by their tag names as shown below.
$('.large').text()
// Europe
$('#medium').text()
// Turkey
$('li[class=small]').html()We can use each() function to iterate through multiple elements. We can return the inner text of the list item using the same HTML code as shown above.
$('li').each(function(i, elem) {
cities[i] = $(this).text();
});This is how you can scrape data from websites using Node.js. You can also use additional methods for extracting the data of child elements of a list or the HTML of a website.
The Importance of Using Node.js With Proxies
You know that proxies act as intermediaries between clients who request resources and the server who provides the resources. There are three different types of proxies, as shown below.
Residential Proxy – This proxy contains IP addresses from local Internet Service Provider (ISP), so the target website can not determine if it is a real person or the scraper browsing the website.
Datacenter Proxy – This type of proxy is from a cloud service provider and is used by a large number of people because it is cheaper than residential proxies.
Mobile Proxy – The mobile proxies are IPs of private mobile devices and work just like residential proxies. They are provided by mobile network operators and are very expensive.

You can use a proxy for web scraping using Python’s requests module. First, you have to import the requests module. Then, you have to create a pool of proxies and iterate them. You can use requests.get() to send the GET request by passing a proxy as a parameter to the URL, as shown below.
import requests
proxy = 'http://114.121.248.251:8080'
url = 'https://ipecho.net/plain'
# Sending a GET request to the url and
# passing the proxy as a parameter.
page = requests.get(url,
proxies={"http": proxy, "https": proxy})
# Printing the content of the requested url.
print(page.text)You will get the below output.
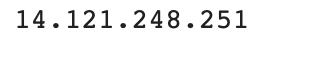
Conclusion on Web Scraping Using Node.js
So far, we discussed that you can extract structured data from websites using the automated method called web scraping. You can scrape the websites using different languages, but in this article, we learnt how to use Node.js to collect data from websites. All we have to do is add code into the index.js file of the project folder. After setting up the project, we can set and make the request to extract the data. Further, we can use the data for various purposes. You know it is not safe to scrape websites. So, you have to use proxies to collect data from your desired website. You can use residential or datacenter proxies, but it is preferred to use the residential proxies as they are fast and can not be easily detected.