




Data Mining – Important Details You Need to Know in 2025

Imagine you are provided with a large dataset containing a thousand columns of data for market analysis. At first glance, you may be overwhelmed. You may not know where to start and how to approach the dataset. You probably understand the dataset and try to find any relationship between the data in the dataset. The
Imagine you are provided with a large dataset containing a thousand columns of data for market analysis. At first glance, you may be overwhelmed. You may not know where to start and how to approach the dataset.
You probably understand the dataset and try to find any relationship between the data in the dataset. The process is known as “Data Mining.” You are unknowingly performing data mining in your everyday tasks. The same thing applies to digital work.
Our world revolves around data, considered one of the most critical resources on the planet. Data engineers are learning how data can evolve our civilization to the next level. Data mining is the first step towards that goal. In the upcoming sections, we will look at data mining and what you need to know about data mining in-depth.
Feel free to jump to any section to learn more about data mining!
Which Is the Best Proxy Server for Web Scraping?
Data: What Is It?
What is data? In simple terms, data is a collection of facts arranged in an unorganized manner. The collection of data is known as information. In the digital world, data is all about numbers. Meaning 0’s and 1’s. It can be either qualitative (data about describing something) or quantitative (data about numbers). When it comes to computer engineering, it is a well-known fact that software is divided into two categories: program and data. We know that data and programs are the instructions that manipulate data in a required way in order to get the desired result.
Data Mining: What Is It?
Data mining is finding the patterns in the dataset, which contains a large amount of data (usually single data called data points). The primary objective of the data mining process is to gather enough information from the given dataset, using any intelligent methods (machine learning, deep learning, statistics, and database system), and transform it into a piece of valuable and meaningful information that you can use later stage. Data mining is an analysis step in KDD (Knowledge Discovery in Database)
Why Is Data Mining Important?
Today, most businesses have started their digital transformation. Data becomes essential for all businesses to improve their strategy and stay afloat against the competition. But with data, you need a tool to analyze the data to develop a plan to reinforce your business. Data mining, the “tool” to analyze the data, is becoming crucial for successful business analytics.
Data mining has become so important that this analysis step is used in every industry, from medicine to food. The main reason for being so important is you can use the information gathered from data mining in artificial intelligence, business intelligence, and other advanced analytics applications/software that have the potential to stream the data in real-time to solve people’s problems with high accuracy in a short period.
Data mining is included in several business core principles and functions to make effective organizational decisions. That includes customer service, digital marketing, both online and offline advertising, manufacturing, maintenance, finance, and HR (Human resources)
How Does Data Mining Work?
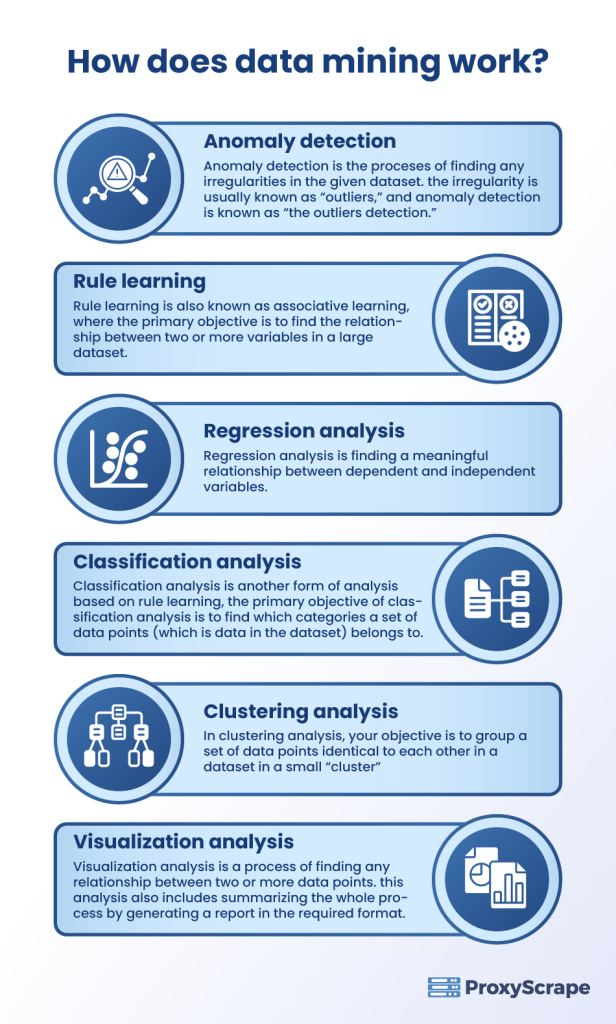
Data mining involves six significant tasks such as:
Anomaly detection.Rule learning. Regression analysis.Classification analysis.Clustering analysis.Visualization analysis.
How Does Data Mining Work?
Anomaly Detection:
Anomaly detection is the process of finding any irregularities in the given dataset. The irregularity is usually known as “outliers,” and anomaly detection is known as “the outliers detection.” The presence of outliers in the dataset influence the prediction of wrong information that you can use in the future. In any machine learning/deep learning algorithm, before feeding the dataset to the algorithm, the data analyst should go through the dataset and check if any anomalies/outliers are present in the given dataset. It is safe to say that anomaly detection is an essential process in all machine learning/deep learning tasks.
Rule Learning:
Rule learning is also known as associative learning, where the primary objective is to find the relationship between two or more variables in a large dataset. For example, an eCommerce website like Amazon or Walmart regularly uses associative learning as one of its core functionalities. It helps to find the relationship between the types of products customers usually buy from their website. You can also use this information to devise iron-clad marketing strategies to increase their business among the target customers. Rule learning is an essential process for both market-based analysis and competitor analysis.
Regression Analysis:
A series of machine learning analyses can be done based on rule learning. One of that analyses is regression analysis. Regression analysis is finding a meaningful relationship between dependent and independent variables. There are two types of variables in any dataset: dependent and independent. Dependent variables (features) are variables that are studied under some form of assumption or rule. Independent variable, from the name, we can easily interpret that the variables do not depend on any other variable in the scope of tasks (which is data analysis). Regression analysis is mainly used for predicting or forecasting the result based on the given dataset.
Classification Analysis:
Classification analysis is another form of analysis based on rule learning. The primary objective of classification analysis is to find which categories a set of data points (which is data in the dataset) belongs to. For example, did you know a titanic dataset is available online for machine learning problems? In that dataset, the objective is to train the algorithm with enough “train” data points and feed the “test” data points to find the outcome of whether the person survived or not. With that, you can classify how many men and women survived and categorize the data based on gender.
Clustering Analysis:
Clustering analysis is more or less similar to classification analysis or at least in its core functionality. In clustering analysis, your objective is to group a set of data points identical to each other in a dataset in a small “cluster.” For example, you have three shapes, square, triangle, and circle. In a dataset, data representing three shapes are randomly arranged. You can use any clustering machine learning algorithms to find an exact number of data points representing each shape and visually give the result.
Visualization Analysis:
From the name you can guess, visualization analysis is a process of finding any relationship between two or more data points. This analysis also includes summarizing the whole process by generating a report in a required format. The main objective here is to create a summary visually that represents the necessary part of the information within the whole dataset.
In all these analyses, the common objective is finding a relationship between two pieces of data. Data mining is finding a connection (patterns) between data in the given dataset to predict a concrete and reliable result and deploy the development in their respective endpoints.
Data mining is a process that you can see more in DevOps (Developer Operations) and MLOps (Machine Learning Operations) than in other sectors. Nowadays, data mining exists in the form of CRISP-DM (Cross Industry Standard Process of Data Mining), which has six phases:
- Business Goal.
- Data Gathering.
- Data Processing.
- Modeling.
- Evaluation.
- Deployment.
Here from data gathering to modeling, data mining is involved deeply. Even though it is not being mentioned as a dedicated process, data mining plays a more important role than any other process in MLOps and DevOps.
As mentioned above, data mining exists in the form of three significant steps in MLOps and DevOps: Data gathering, data processing, and modeling. You can do the data processing step with the help of various statistical methods and approaches. Choosing to model is easy since many modeling algorithms are available. You need to inject the data into the model to get the result. The complex and tedious process would likely be data gathering.
If the data is readily available, it should be a piece of cake to carry out other steps. But that won’t be the case most of the time. You need to gather data online. This is where the tedium comes in. Billions of data are available online, and you need only relevant data for your tasks. Procuring data one by one is not possible. You need a tool that can gather data from the target source and save it in the desired format, so you can process the required data after collecting it. This tool would be “Web Scraping.“
Web Scraping: What Is It?
Web scraping is more than a tool; it’s a technique that involves gathering a large amount of data (in GigaBytes or TeraBytes) from the target source(s). There are two parts involved in web scraping: Crawler and Scraper. Crawler and Scraper are bots built by programming scripts, such as Python. First, the Crawler will go through the content in the target source and send the information to the Scraper. Based on the information given by the Crawler, the Scraper starts to gather the information required from the original and send it to the user in real-time. This process is also called “streaming data.”
Web scraping is in the grey area. In some countries, you can perform web scraping without any difficulties. In others, you cannot perform web scraping without security measures. Even though you are scraping public data, you need to make sure that you are not bringing harm to the original owner of the data in any shape or form, and you also need to find a way to hide your IP address while web scraping.
What is the best way to scrape data without bringing harm to the owner and hiding your IP address?
The answer is a proxy server.
A Proxy Server: What Is It?
A proxy server is an intermediary server that sits between you (the client) and the target server (online). Instead of routing your request and internet traffic directly to the target server, a proxy server can reroute the traffic and request through its server and send it to the target server. This “three-way handshake” helps to mask your IP address and make you anonymous online. So, how does this help in web scraping?
In web scraping, you need to send a lot of requests to the target server in a short amount of time so you can gather a large amount of data. But it is not human behavior to send that many requests to the target server in a short time. This is considered a red flag from the target server and blocks your IP address. This hinders your web scraping process, but the probability of getting an IP block is low if you hide your IP address deep enough. This is where a proxy server shines at its best.
Which Is the Best Proxy Server for Web Scraping?
ProxyScrape is one of the most popular and reliable proxy providers online. Three proxy services include dedicated datacentre proxy servers, residential proxy servers, and premium proxy servers. So, which is the best proxy server for web scraping/data mining? Before answering that questions, it is best to see the features of each proxy server.
A dedicated datacenter proxy is best suited for high-speed online tasks, such as streaming large amounts of data (in terms of size) from various servers for analysis purposes. It is one of the main reasons organizations choose dedicated proxies for transmitting large amounts of data in a short amount of time.
A dedicated datacenter proxy has several features, such as unlimited bandwidth and concurrent connections, dedicated HTTP proxies for easy communication, and IP authentication for more security. With 99.9% uptime, you can rest assured that the dedicated datacenter will always work during any session. Last but not least, ProxyScrape provides excellent customer service and will help you to resolve your issue within 24-48 business hours.
Next is a residential proxy. Residential is a go-to proxy for every general consumer. The main reason is that the IP address of a residential proxy resembles the IP address provided by ISP. This means getting permission from the target server to access its data will be easier than usual.
The other feature of ProxyScrape’s residential proxy is a rotating feature. A rotating proxy helps you avoid a permanent ban on your account because your residential proxy dynamically changes your IP address, making it difficult for the target server to check whether you are using a proxy or not.
Apart from that, the other features of a residential proxy are: unlimited bandwidth, along with concurrent connection, dedicated HTTP/s proxies, proxies at any time session because of 7 million plus proxies in the proxy pool, username and password authentication for more security, and last but not least, the ability to change the country server. You can select your desired server by appending the country code to the username authentication.
The last one is the premium proxy. Premium proxies are the same as dedicated datacenter proxies. The functionality remains the same. The main difference is accessibility. In premium proxies, the proxy list (the list that contains proxies) is made available to every user on ProxyScrape’s network. That is why premium proxies cost less than dedicated datacenter proxies.
So, which is the best proxy server for data mining? The answer would be “residential proxy.” The reason is simple. As said above, the residential proxy is a rotating proxy, meaning that your IP address would be dynamically changed over a period of time which can be helpful to trick the server by sending a lot of requests within a small time frame without getting an IP block. Next, the best thing would be to change the proxy server based on the country. You just have to append the country ISO_CODE at the end of the IP authentication or username and password authentication.
FAQs:
FAQs:
1. What is data mining?
2. Are there any types of data mining?
3. Is web scraping a part of data mining?
Conclusion:
Data is one of the most valuable resources on Earth. To evolve our generation to the next level, you need data. But only with data can we not achieve that behemoth of goal. It would be best if you had best practices and tools to decode that data and use it meaningfully.
Data mining is an excellent step toward decoding data. It gives information on how data correlate and how we can use that relationship to develop our technology. Web scraping helps gather data and acts as a catalyst in decoding data. Using a proxy server, specifically a residential proxy, is recommended during the web scraping process to carry out the tasks effectively.
This article hopes to give in-depth information about data mining and how web scraping influences data mining.