





Businesses use web scrapers to collect data from various websites. The data businesses scrape extracts product details, pricing details, and access public records. Companies use this data to improve business and marketing strategies. If scraping is not done properly, then IP blacklists are a common issue. You may scrape without proxies using some tools that
Businesses use web scrapers to collect data from various websites. The data businesses scrape extracts product details, pricing details, and access public records. Companies use this data to improve business and marketing strategies. If scraping is not done properly, then IP blacklists are a common issue.
You may scrape without proxies using some tools that you can access from your desktop or from a web server. You can perform small-scale data scraping such as scraping data from URLs using some tools instead of using proxies as they are slower and incur additional costs. Let’s look at some of the methods to scrape data without proxies.
Scrape Data using Your Own IP Address
You can make use of your own IP address using a scraping tool without the target website blocking it. However, if a website identifies that you are scraping data from their website, they will blacklist your IP, which makes it inaccessible to collect further data using the same IP address.
Using your own IP address to scrape data is slow compared to scraping data using proxies but it is ethical and less risky because it will not affect the performance of the site and the speed of other users. Websites identify scrapers by the high download rates or unusual traffic patterns or performing certain tasks repeatedly on the website. These websites may use honeypot traps, which are links invisible to the normal user but identified by the scraper.
Also, the business program webpages to block spiders and crawlers to optimize the server load. When you scrape using your own IP address, you appear more human and can avoid the target website blocking you.
Scrape Data by Hiding Your IP Address
There are many tools to scrape data without proxies without having the target website blocking your IP address. One tool is The onion routing (Tor) which masks your IP address, but it is not suitable for scraping or automation.
Tor has around 20,000 IP addresses to use to mask your real IP address but all these are marked and the sources are identifiable. If you use an IP address from the Tor network to scrape the website and the website, it identifies you in turn, then it results in the website blocking the exit nodes of the Tor network. When a website blocks the Tor network’s IP address, it prevents other Tor users from accessing the website.
The disadvantage of using these tools is that they can slow the process because they pass traffic through multiple different nodes before reaching a website. The website may also block IP addresses if it detects multiple requests from a single IP address.
Scrape Data Using Rotating User Agents
The HTTP request header permits a characteristic string that tells the peers in the network the type of operating system and the browser type of the web server. A user agent is unique to every web server and the target website identifies this user agent if you do the same to crawl the website.
Most browsers allow you to rotate your user agent. You can create a list of user-agent strings with different browser types from popular browsers to imitate well-known crawlers like Googlebot. You can also use a tool to automatically change your user agent and collect the same data as Google crawls a website.
Scrape Data Using a Headless Browser
A headless browser is a web browser or software that accesses web pages to provide results without any identifiable graphical user interface. There are many headless browsers such as Google’s Puppeteer, Selenium, and PhantomJS.
Websites cannot detect headless browsers during web scraping and they automate the process through a command-line interface. They don’t require the web pages to load during crawling and can crawl more pages at the same time.
The only disadvantage is that these browsers consume RAM, CPU, and bandwidth. It is suitable to use the headless browser only when the CPU resources are high. Headless browsers require Javascripts for scraping the web content that is otherwise not accessible through a server’s raw HTML response.
Scrape Data Using a Rotating Proxy
A rotating proxy assigns a new IP address for every new connection from a proxy pool. Rotating IPs have a lower chance of websites blocking them as the service provider assigns fresh IP addresses from its vast pool of IP addresses at regular intervals. Rotating IPs provide anonymity crucial for web scraping and also avoids the risk of blocking.
A new IP address is allotted for every new request from a user. The websites have difficulty detecting or blocking the proxy as it changes the IP address frequently.
When you use a rotating proxy for web scraping, the internet service provider (ISP) provides a new IP address from the pool of IP addresses. The advantage of using a rotating proxy is that the ISPs have more IP addresses than the users connected to them.
It distributes the next available IP address for the proxy to connect. The IP address is put back into the pool for the next user, when a user disconnects, it takes and puts it back in the. The server will rotate IPs from the pool for all the concurrent connection requests sent to it.
The user can also set the frequency of rotating the IP addresses with a sticky session or sticky IP. And maintain the same IP address until they complete a task. A sticky session will maintain the proxy with the same IP address until you finish scraping.
Scrape Data Using Google Cloud Platform
A web scraper can run on a Google Compute Engine virtual machine to scrape the internal and external links of a given domain to a database. Googlebot is a web crawler that visits the websites to collect documents from the site to build a searchable index for the Google search engine. On the target website, it would appear it’s a Googlebot and not a scraper, so the websites do not block your scraper. Therefore, there are higher chances that websites will not block your scraper if you use Google Compute Engine for hosting your scrapers.
Scrape Data Using CAPTCHA Solving Service
When you scrape data without proxies, you need to bypass CAPTCHAs as they detect bot traffic on websites. You can bypass this layer of security using a CAPTCHA solving service. Most CAPTCHA solving services solve all types of patterns such as text, image, sound, and reCAPTCHA. These services incur extra costs and increase the overhead of scraping data from websites.
Scrape Data from Google Cache
Most websites allow Google to crawl their content because it helps index the content and return when the user searches for it. This means that Google has already downloaded the content and it is available in its cache. You can access the cached pages to access the information that you need.
To accomplish this, go to the Google search engine and type the word or the name of the website. From the results, take the page that you want to scrape. Click on the three dots near the title of the page, and you can see the button “Cached.” Then, click on it, and you can see the cached page immediately.
You can get the latest updates that are done as recently as a few hours ago on the site as Google crawls regularly. The screenshot below shows an example of the results shown by Google and you can see the three dots next to the title.

Scrape data from Google’s cache
After you click on the three dots, you get this page from where you can get the cached data.
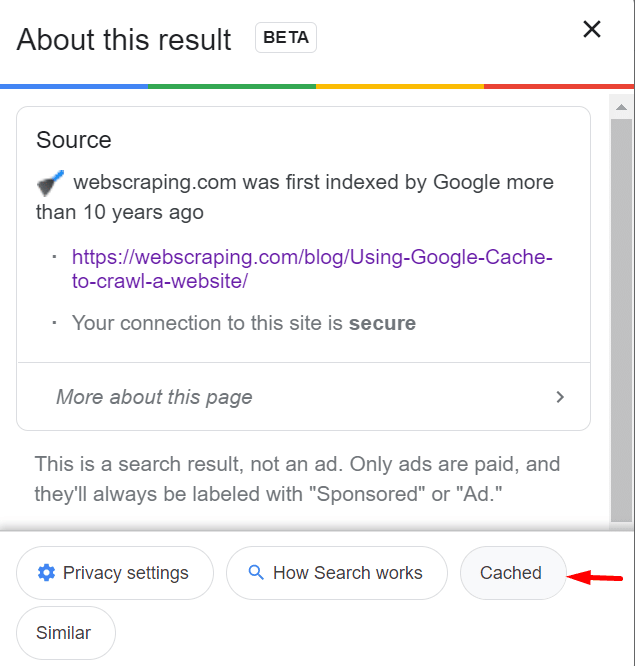
Access cached data from Google
Scrape Data with Dynamic Web Queries
It is an easy and efficient scraping method to set the data feed from an external website into a spreadsheet. The dynamic web queries feed the latest data from the websites regularly. It’s not just a one-time static operation and that’s why it is called dynamic. The process to do it is as follows:
- Open a new worksheet in Excel.
- Click the cell where you wish to import the data.
- Click the Data -> Get Data -> From Other Sources ->From Web.
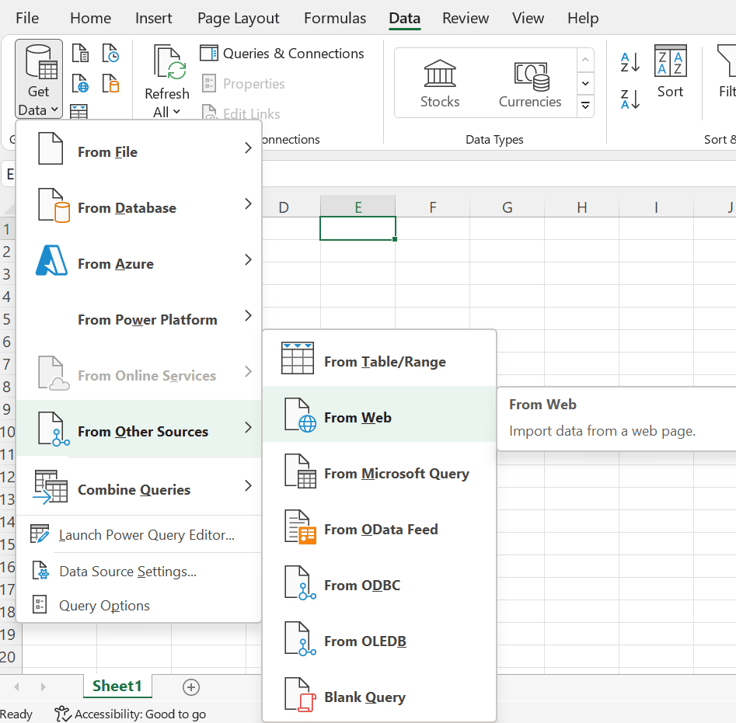
Scrape data with web queries
- Mention the URL from where you wish to scrape in the dialog box.
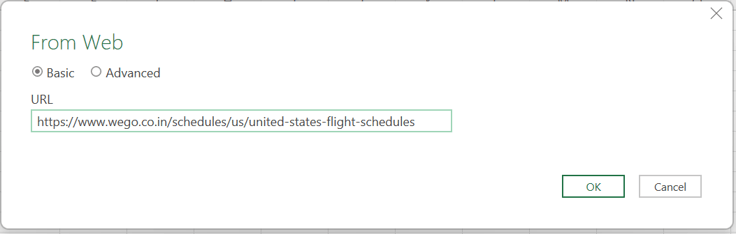
Insert the URL from where you wish to scrape
- Click OK.
- In the Access Web Content dialog box, click Connect.

Setting anonymous access
- You get the connection message while Excel tries to connect to the website that you want to access.
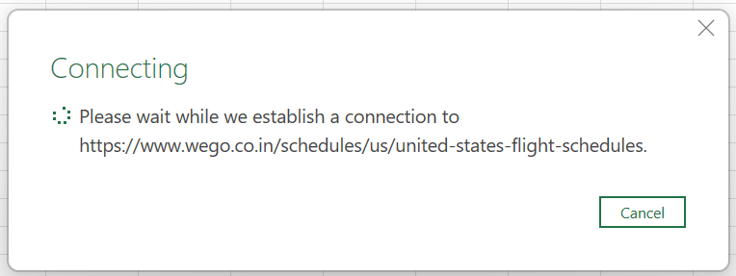
Establish connection
- You can see the tables scraped and available for use.

Tables scraped from the website
Final Thoughts
Web scraping involves scraping product details, prices, and new product launches from the competitor’s websites. The challenge is to scrape data without websites blocking you. If you are performing a small-scale scraping, then you can use any of the methods mentioned above. Small-scale scraping includes mining some structured information such as discovering hyperlinks between documents.
Though there are many ways of scraping data without proxies, proxies are preferred for scraping. Proxies are faster and more reliablewhen you are scraping a huge data set from a website. A datacenter proxy or residential proxy is best to ensure anonymity and privacy. ProxyScrape offers a variety of proxies to use for all your business needs. Keep checking our website to know more about proxies and to learn about them.