





eBay is one of the world’s largest online marketplaces, hosting millions of products across various categories. Scraping eBay can be invaluable for tasks like:
- Price Comparison
- Market Analysis
- Tracking Product Trends
In this guide, we’ll show you how to create a simple Python script to search for a keyword, extract product details like title, price, currency, availability, reviews, and ratings, and save the data into a CSV file. This tutorial is great for beginners who want to learn web scraping the right way, with tips on respecting terms of service and using proxies responsibly.
Skip the Explanation? Here's the Full Code
If you’re just looking for the full implementation, here’s the complete Python script for scraping product details from eBay using proxies. Copy and paste it into your environment to get started:
import re
import csv
import time
import requests
from bs4 import BeautifulSoup
proxies = {
"http": "http://username:[email protected]:6060",
"https": "http://username:[email protected]:6060",
}
def get_product_information(product_url) -> dict:
r = requests.get(product_url, proxies=proxies)
soup = BeautifulSoup(r.text, features="html.parser")
product_title = soup.find("h1", {"class": "x-item-title__mainTitle"}).text
product_price = soup.find("div", {"class": "x-price-primary"}).text.split(" ")[-1]
currency = soup.find("div", {"class": "x-price-primary"}).text.split(" ")[0]
# locate the element that holds quanity number of product
quantity_available = soup.find("div", {"class":"x-quantity__availability"})
if quantity_available is not None:
# Using regex check if we can locate the strings that holds this number
regex_pattern = r"\d+\savailable"
if re.search(regex_pattern, quantity_available.text) is not None:
quantity_available = re.search(regex_pattern, quantity_available.text).group()
# After string is located we extract the number by splitting it by space and selecting the first element.
quantity_available = quantity_available.split(" ")[0]
else:
quantity_available = "NA"
total_reviews = soup.find("span", {"class":"ux-summary__count"})
if total_reviews is not None:
total_reviews = total_reviews.text.split(" ")[0]
else:
total_reviews = "NA"
rating = soup.find("span", {"class":"ux-summary__start--rating"})
if rating is not None:
rating = rating.text
else:
rating = "NA"
product_info = {
"product_url": product_url,
"title": product_title,
"product_price": product_price,
"currency": currency,
"availability": quantity_available,
"nr_reviews": total_reviews,
"rating": rating
}
return product_info
def save_to_csv(products, csv_file_name="products.csv"):
# Write the list of dictionaries to a CSV file
with open(csv_file_name, mode='w', newline='') as csv_file:
# Create a csv.DictWriter object
writer = csv.DictWriter(csv_file, fieldnames=products[0].keys())
# Write the header (keys of the dictionary)
writer.writeheader()
# Write the rows (values of the dictionaries)
writer.writerows(products)
print(f"Data successfully written to {csv_file_name}")
def main(keyword_to_search: str):
products = []
r = requests.get(f"https://www.ebay.com/sch/i.html?_nkw={keyword_to_search}", proxies=proxies)
soup = BeautifulSoup(r.text, features="html.parser")
for item in soup.find_all("div", {"class": "s-item__info clearfix"})[2::]:
item_url = item.find("a").get("href")
product_info: dict = get_product_information(item_url)
print(product_info)
# Adding a 1-second delay between requests to avoid overloading the server and reduce the risk of being blocked
time.sleep(2)
products.append(product_info)
# save data to csv
save_to_csv(products)
if __name__ == '__main__':
keywords = "laptop bag"
main(keywords)Please remember to update the proxies variable with a new username and password before using them.
How We’ll Scrape eBay
Our method simplifies the process, focusing on four key functions:
- Searching a Keyword: Discover products by entering a search term (e.g., “laptop bags”) to fetch relevant items.
- Extracting Product URLs: Collect URLs of listed products on the search result's first page to streamline data collection.
- Extracting Product Information: For each product URL, we will navigate to the product page to retrieve vital information.
- Saving Data: Save the extracted data into a CSV file for efficient access and analysis.
Prerequisites
Starting with the right tools is crucial. You'll need to:
Install Python:
- Here's a helpful guide to installing Python.
Set Up Your Development Environment:
- Select the directory you want to place this project on. Set up a virtual environment to maintain clean, isolated dependencies.
mkdir ebay_scraping
cd ebay_scraping
python -m venv venv
source env/bin/activate # On Windows use: venv\Scripts\activate
pip install requests bs4Proxies Setup:
In this example we will be using rotating Proxyscrape Residential Proxies in order to maintain anonymity and protect the private ip from being blacklisted.
Script Explanation
Step 1: Importing Libraries and Proxies
We start by importing necessary libraries for this web scraping project which include:
- CSV: this module provides classes to read and write tabular data in CSV format. It lets programmers easily write data in Excel's preferred format or read data from files generated by Excel without knowing the precise CSV format details.
- Requests: this module allows you to send HTTP requests using Python.
- BeautifulSoup4 is a powerful html parser designed to extract the information you need from an html structure.
Required Imports:
import csv
import time
import requests
from bs4 import BeautifulSoupProxy Setup:
In order to keep your ip private thus minimizing the chances of getting your ip blacklisted from specific websites it is recommended to perform web scraping activities under the shield of proxies, as mentioned above we will be using rotating Proxyscrape Residential Proxies for this tutorial but you can use other proxies or no proxies at all.
proxies = {
"http": "http://username:[email protected]:6060",
"https": "http://username:[email protected]:6060",
}Step 2: Getting Search Results
Let's begin by explaining the search process we'll use in this tutorial. We'll query the eBay URL with a “laptop bag” keyword, as shown in this picture:
We will use the queried URL to send a request with request.get(). Once we receive a response, we'll parse the HTML content using BeautifulSoup (bs4) to extract each product's URL. The image below shows where each product URL is located within the HTML.
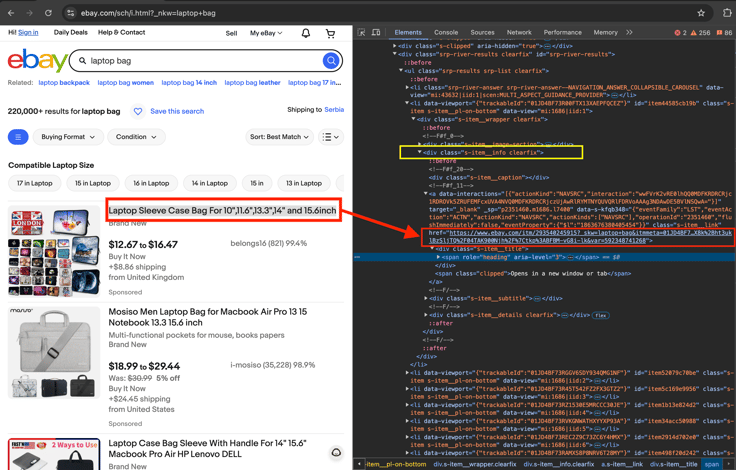
The product link is found within a <div> element with the class s-item__info clearfix. To extract these links, we use BeautifulSoup (bs4) to search for all <div> elements with this specific class. Once we've located these elements, we iterate through each one to find <a> elements and extract the href attribute, which contains the product URL.
def main(keyword_to_search: str):
products = []
r = requests.get(f"https://www.ebay.com/sch/i.html?_nkw={keyword_to_search}", proxies=proxies)
soup = BeautifulSoup(r.text, features="html.parser")
for item in soup.find_all("div", {"class": "s-item__info clearfix"})[2::]:
item_url = item.find("a").get("href")
product_info: dict = get_product_information(item_url)
# Adding a 1-second delay between requests to avoid overloading the server and reduce the risk of being blocked
time.sleep(1)
products.append(product_info)
# save data to csv
save_to_csv(products)Step 3: Extracting Product Information
Introducing the get_product_information function. This function takes a product URL as input, sends a request to that URL, and then utilizes BeautifulSoup (bs4) to parse product information using specific rules and regex patterns.
def get_product_information(product_url) -> dict:
r = requests.get(product_url, proxies=proxies)
soup = BeautifulSoup(r.text, features="html.parser")
product_title = soup.find("h1", {"class": "x-item-title__mainTitle"}).text
product_price = soup.find("div", {"class": "x-price-primary"}).text.split(" ")[-1]
currency = soup.find("div", {"class": "x-price-primary"}).text.split(" ")[0]
# locate the element that holds quanity number of product
quantity_available = soup.find("div", {"class":"x-quantity__availability"})
if quantity_available is not None:
# Using regex check if we can locate the strings that holds this number
regex_pattern = r"\d+\savailable"
if re.search(regex_pattern, quantity_available.text) is not None:
quantity_available = re.search(regex_pattern, quantity_available.text).group()
# After string is located we extract the number by splitting it by space and selecting the first element.
quantity_available = quantity_available.split(" ")[0]
else:
quantity_available = "NA"
total_reviews = soup.find("span", {"class":"ux-summary__count"})
if total_reviews is not None:
total_reviews = total_reviews.text.split(" ")[0]
else:
total_reviews = "NA"
rating = soup.find("span", {"class":"ux-summary__start--rating"})
if rating is not None:
rating = rating.text
else:
rating = "NA"
product_info = {
"product_url": product_url,
"title": product_title,
"product_price": product_price,
"currency": currency,
"availability": quantity_available,
"nr_reviews": total_reviews,
"rating": rating
}
return product_infoFinally, we organize the parsed product entities into a dictionary, which is then returned by the function.
Step 4: Saving Results
It's time to store these results in a CSV file using Python's native csv library. The save_to_csv(products) function accepts products as an input, which is a list of dictionaries containing product details as previously described. This data is then saved into a CSV file named after the csv_file_name argument, which defaults to "products.csv".
def save_to_csv(products, csv_file_name="products.csv"):
# Write the list of dictionaries to a CSV file
with open(csv_file_name, mode='w', newline='') as csv_file:
# Create a csv.DictWriter object
writer = csv.DictWriter(csv_file, fieldnames=products[0].keys())
# Write the header (keys of the dictionary)
writer.writeheader()
# Write the rows (values of the dictionaries)
writer.writerows(products)
print(f"Data successfully written to {csv_file_name}")Conclusion
In this tutorial, we demonstrated how to scrape eBay by building a Python script that searches for a keyword, extracts product details, and saves the data into a CSV file. This process highlights essential scraping techniques like handling HTML elements, using proxies for anonymity, and respecting ethical scraping practices. This script can be further improved by incorporating pagination functionality and the ability to process multiple keywords.
Always remember to scrape responsibly, adhere to website terms of service, and use tools like rate limiting to avoid disruptions. To make your scraping tasks more reliable and efficient, consider exploring our high-quality proxy services at ProxyScrape. Whether you need residential, datacenter, or mobile proxies, we’ve got you covered. Check out our offerings to take your web scraping projects to the next level!
Happy scraping!