





In this blog post, we'll guide you through the process of scraping images from websites using Python. You'll learn how to get started with popular libraries, handle potential pitfalls, and even explore advanced techniques to take your web scraping skills to the next level.
The Basics of Scraping Images with Python
To start scraping images with Python, you'll need to familiarize yourself with some key libraries that make this task easier. The most popular choices are BeautifulSoup, Scrapy, and Requests.
BeautifulSoup for Extracting Image URLs
BeautifulSoup is a Python library used for parsing HTML and XML documents. It creates a parse tree from page source codes that can be used to extract data easily.
Here's a simple example of how to extract image URLs using BeautifulSoup:
Step 1: Install BeautifulSoup and Requests:
pip install bs4 requests
Step 2: Extract Image URLs:
import requests
from bs4 import BeautifulSoup
url = 'https://books.toscrape.com/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
images = soup.find_all('img')
This code fetches the HTML content of the specified URL, parses it with BeautifulSoup, and then finds all the `<img>` tags, printing out their `src` attributes.
Downloading Images with Python
Once you've extracted the image URLs, the next step is to download them. The Requests library is perfect for this task due to its simplicity and ease of use.
Using Requests to Download Images
Here’s how you can download images using Requests:
Download Image from URL:
for ind, img in enumerate(images):
img_data = requests.get(url+img['src']).content
with open(f'image_{ind+1}.jpg', 'wb') as handler:
handler.write(img_data)
This script sends a GET request to the image URL and writes the binary content of the image to a file.
Handling Errors and Exceptions
It’s important to handle errors and exceptions to ensure your script runs smoothly even when issues arise. Here's an enhanced version of the previous script:
Error Handling:
for ind, img in enumerate(images):
try:
img_data = requests.get(url+img['src']).content
with open(f'image_{ind+1}.jpg', 'wb') as handler:
handler.write(img_data)
except Exception as e:
print(f"An error occurred during the extraction of image \n Image Url: {img['src']} \n Error: {e}")
This code snippet includes a try-except block to catch any errors that might occur during the download process.
Advanced Techniques for Image Scraping
For more complex scraping tasks, such as scraping multiple pages or entire websites, Scrapy is a powerful library that can handle these scenarios efficiently.
Using Scrapy for Complex Tasks
Scrapy is an open-source and collaborative web crawling framework for Python. It’s designed for speed and efficiency, making it ideal for large-scale scraping projects.
Step 1: Install Scrapy:
pip install scrapy
Step 2: Create a Scrapy Project:
scrapy startproject image_scraper
cd image_scraper
Step 3: Define a Spider:
Create a spider file (`spiders/image_spider.py`) with the following content:
import scrapy
class ImageSpider(scrapy.Spider):
name = 'imagespider'
start_urls = ['https://books.toscrape.com/']
def parse(self, response):
# Extract image URLs and convert them to absolute if necessary
for img in response.css('img::attr(src)').getall():
abs_img_url = response.urljoin(img)
yield {'image_url': abs_img_url}
# Find the link to the next page and create a request for it
next_page = response.css('a.next::attr(href)').get()
if next_page is not None:
next_page_url = response.urljoin(next_page)
yield response.follow(next_page_url, self.parse)
This simple Scrapy spider starts at the given URL, extracts all image URLs, and follows the next page links to continue scraping.
Enhancing Your Image Scraping Projects
To further improve your scraping projects, consider using APIs to access high-quality images and automating your tasks for efficiency.
Using APIs for Image Scraping
APIs provide a reliable and legal way to access images. Many websites offer APIs that allow you to search and download images programmatically. One of these websites is Unsplash API.
Example with Unsplash API:
import requests
# Replace 'YOUR_ACCESS_KEY' with your actual Unsplash Access Key
api_url = "https://api.unsplash.com/photos/random"
headers = {"Authorization": "Client-ID YOUR_ACCESS_KEY"}
params = {"query": "nature"}
try:
response = requests.get(api_url, headers=headers, params=params)
response.raise_for_status() # This will raise an exception for HTTP errors
data = response.json()
image_url = data['urls']['full']
print(image_url)
except requests.exceptions.HTTPError as err:
print(f"HTTP error occurred: {err}")
except Exception as err:
print(f"An error occurred: {err}")
This script uses the Unsplash API to fetch a random nature image.
Automating Image Scraping Tasks
Automation saves time and ensures your scraping tasks run smoothly without manual intervention. Tools like cron jobs on Unix systems or Task Scheduler on Windows can schedule your scripts to run at regular intervals.
Cron jobs on Unix systems - Crontab:
Crontab is a powerful utility in Unix-like operating systems for scheduling tasks, known as "cron jobs" to run automatically at specified times. Let's see how we can schedule a task using Crontab.
Understanding Crontab Syntax:
A crontab file consists of command lines, where each line represents a separate job. The syntax is as follows:
MIN HOUR DOM MON DOW CMD- MIN: Minute field (0 to 59)
- HOUR: Hour field (0 to 23)
- DOM: Day of Month (1 to 31)
- MON: Month field (1 to 12)
- DOW: Day of Week (0 to 7 where 0 and 7 represent Sunday)
- CMD: The command to run (in this case it will be the executable of your python script)
Here is an example of running a python script daily at 8:00PM
0 20 * * * /usr/bin/python3 /path/to/Image_Scraper.pyUsing Task Scheduler (Windows):
- Open Task Scheduler (Use the search bar on windows and search for "Task Scheduler")
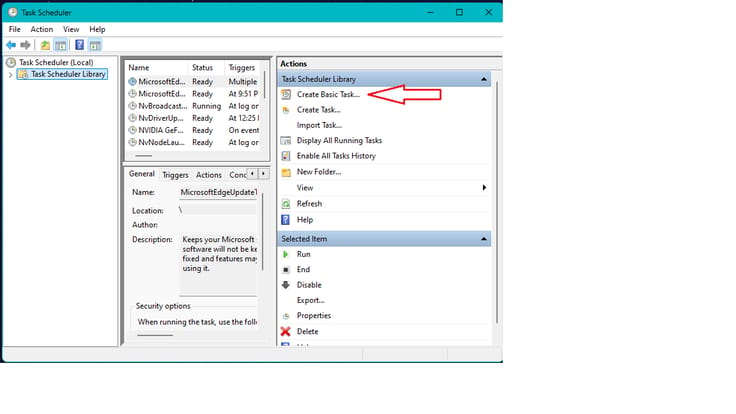
- Click on "Create Basic Task"
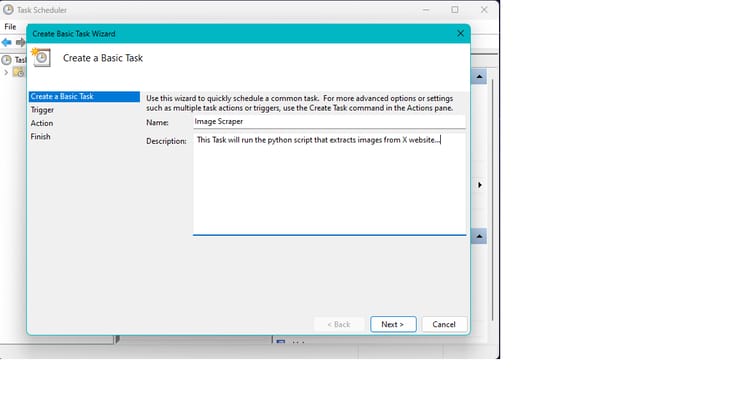
- Provide a name and description and click "Next"
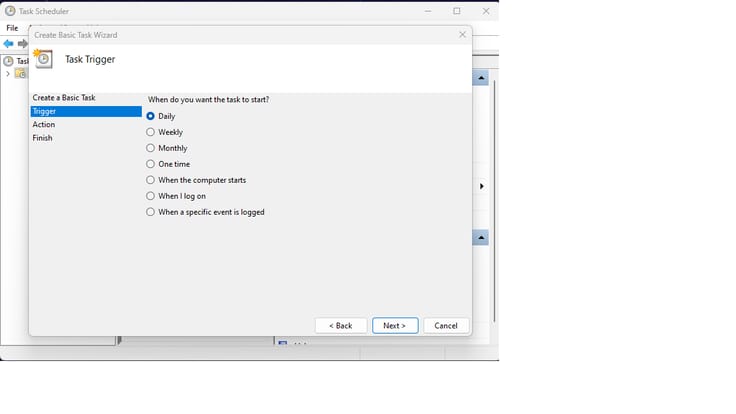
- Select granularity or the interval you need to run this task and click "Next"
- Now make sure "Start a program" is checked and click "Next"
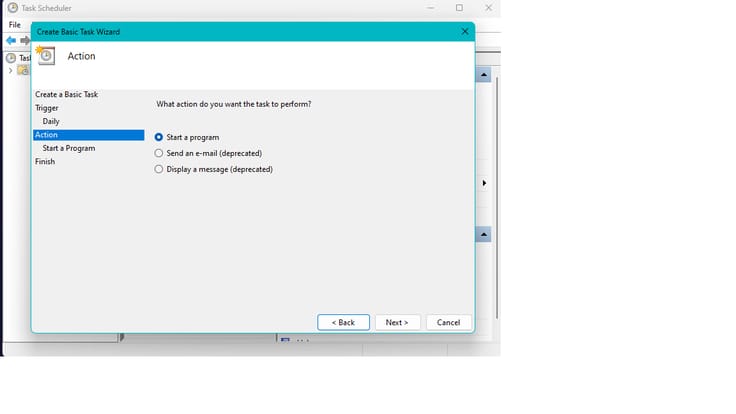
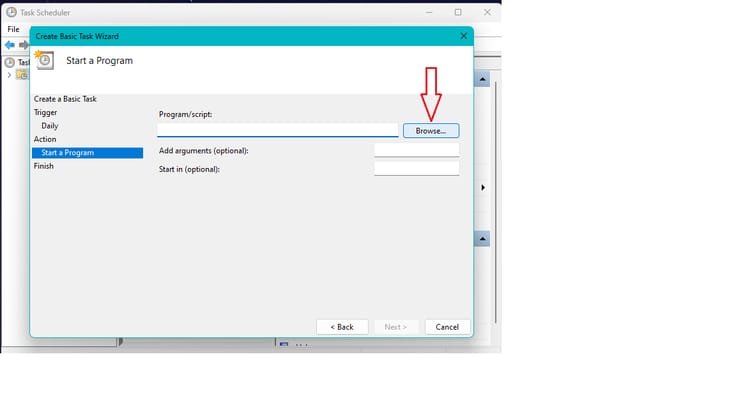
- Provide the path to your python script by click on "Browse". Optionally if you have to provide any arguments for your python script you can do so by adding them on "Add arguments" fields and click "Next"
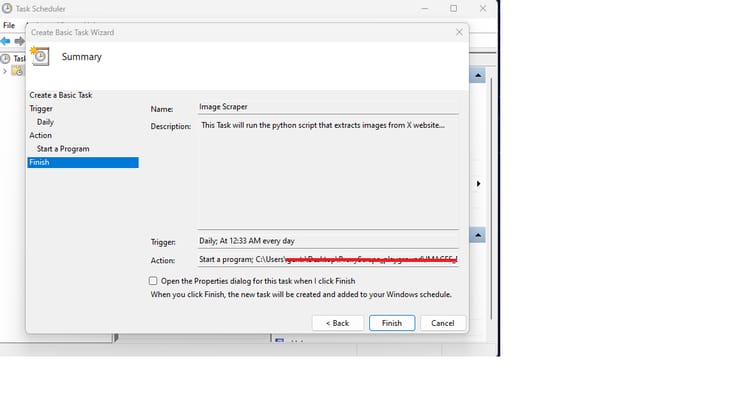
- As the last step, you simply click "Finish" and just like that, this task is ready to run in the specified interval.
Conclusion
In this blog post, we've explored how to scrape images from websites using Python. We've covered the basics with BeautifulSoup and Requests, advanced techniques with Scrapy, and ethical scraping practices. Additionally, we've discussed how to enhance your scraping projects using APIs and automation tools like Windows Task Scheduler.
Image scraping is a powerful skill that can enhance your data acquisition capabilities and open up new possibilities for your projects.
Happy scraping!