





Web scraping has become an essential tool in the digital age, especially for web developers, data analysts, and digital marketers. Imagine being able to extract valuable information from websites quickly and efficiently. This is where MechanicalSoup comes into play. This guide will explore the intricacies of using MechanicalSoup for web scraping, offering practical insights and tips to get you started.
The Role of MechanicalSoup in Web Scraping
MechanicalSoup is a Python library designed to simplify web scraping by providing a straightforward interface to automate interactions with web pages. It efficiently handles forms, links, and can navigate sites requiring basic user actions such as form submissions and link navigation. This makes it ideal for automating tasks on websites with static content where complex user behaviors are not required.
Getting Started Setting Up MechanicalSoup for Web Scraping
Before we dive into the specifics of web scraping, let's first set up MechanicalSoup. The installation process is straightforward and can be completed in a few steps.
Installing MechanicalSoup
To install MechanicalSoup, you'll need Python installed on your machine. You can then use pip, Python's package installer, to install MechanicalSoup. Open your terminal and type the following command:
pip install mechanicalsoup
Setting Up Your Environment
Once MechanicalSoup is installed, setting up your development environment is crucial. You'll need a code editor, such as Visual Studio Code or PyCharm, to write and run your Python scripts. Ensure you also have "BeautifulSoup" and "requests" libraries installed.
First Steps with MechanicalSoup
Creating your first web scraping script with MechanicalSoup involves a few basic steps. Start by importing the necessary libraries and initializing a browser object. Here's a simple example to get you started:
import mechanicalsoup
browser = mechanicalsoup.StatefulBrowser()
browser.open("https://www.scrapethissite.com/pages/")
Understanding the Basics of Web Scraping with MechanicalSoup
Now that we have MechanicalSoup set up let's explore the basics of web scraping. Understanding these fundamentals will enable you to build more complex scraping scripts.
Handling Forms
In MechanicalSoup the "select_form()" method is used to locate and handle forms.
The argument to select_form() is a CSS selector. In the code example below, we are using this site to fill a simple one-field search form. Since in our case there’s only one form in the page, browser.select_form() will do the trick. Otherwise you would have to enter the css selector to the select_form() method. Additionally, to view the fields on the form, you can utilize the print_summary() method. This will provide you with detailed information about each field. Given that the form contains two types of elements—text fields and buttons—we will only have to fill the text field and then submit the form:
import mechanicalsoup
browser = mechanicalsoup.StatefulBrowser()
browser.open("https://www.scrapethissite.com/pages/forms/?page_num=1")
# Select the form
search_form = browser.select_form()
print(search_form.print_summary())
search_form.set("q",'test')
browser.submit_selected()Here is the result of the code above.
<input class="form-control" id="q" name="q" placeholder="Search for Teams" type="text"/>
<input class="btn btn-primary" type="submit" value="Search"/>Pagination Handling
Web scraping often involves dealing with multiple pages of data. MechanicalSoup does not directly offer a feature to paginate through pages using pagination links.
In the example website that we are using pagination looks like this:

Here how the HTML Structure looks like:
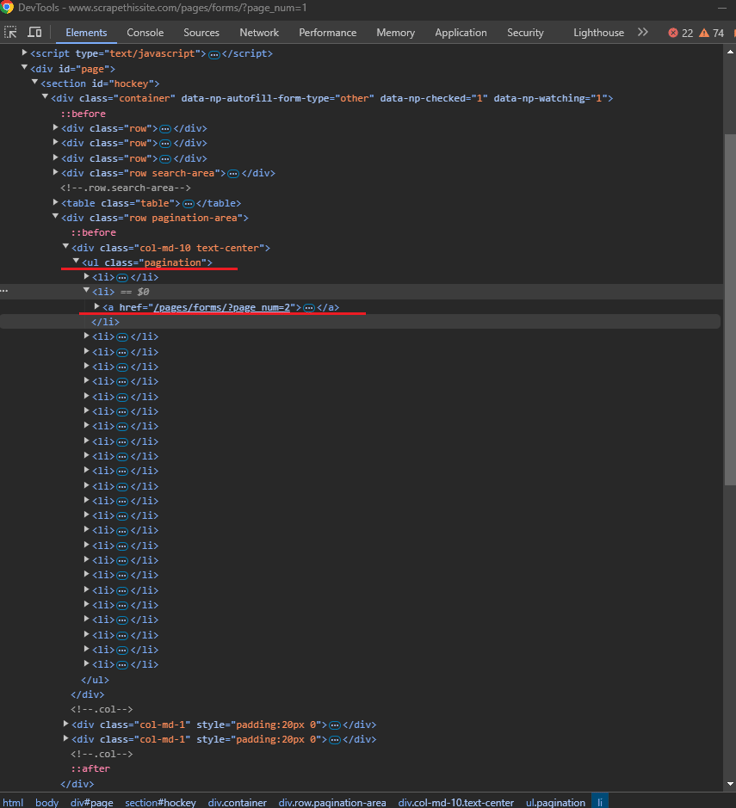
So what we will do is first select the list that holds the pagination links with "browser.page.select_one('ul.pagination')".
Then with ".select('li')[1::]" we select all "<li>" elements inside 'pagination' list starting from the second element. This will return a list of "<li>" elements and then we paginate each one of them in a "for loop" starting from the second element and for each "<li>" element we extract the "<a>" tag and then use it in "follow_link()" method to navigate to that page.
Here is the full example:
import mechanicalsoup
browser = mechanicalsoup.StatefulBrowser()
browser.open("https://www.scrapethissite.com/pages/forms/?page_num=1")
for link in browser.page.select_one('ul.pagination').select('li')[1::]:
next_page_link = link.select_one('a')
browser.follow_link(next_page_link)
print(browser.url)Setting up Proxies
When scraping websites or automating web interactions, using proxies can be crucial for bypassing geo-restrictions, managing rate limits, or preventing IP bans. Using MechanicalSoup in combo with "requests" library we can seamlessly integrate proxy configurations, allowing you to leverage these benefits effectively. Here's how you can set up proxies in MechanicalSoup for your web scraping tasks:
import mechanicalsoup
import requests
def create_proxy_browser():
# Define your proxy configuration (example values)
proxies = {
"http": "rp.proxyscrape.com:6060:username:password",
"https": "rp.proxyscrape.com:6060:username:password",
}
# Create a session object with proxy settings
session = requests.Session()
session.proxies.update(proxies)
# Optionally, you can add headers or other session settings here
session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
})
# Create a MechanicalSoup StatefulBrowser using the configured session
browser = mechanicalsoup.StatefulBrowser(session=session)
return browser
# Usage
browser = create_proxy_browser()
response = browser.open("https://www.scrapethissite.com/pages/forms/?page_num=1")
print(response.text) # Outputs the content of the pageEthical and Legal Considerations in Web Scraping
Web scraping can raise ethical and legal concerns. It's essential to understand these considerations to avoid potential issues.
Respecting Website Policies
Always check a website's terms of service before scraping. Some sites explicitly prohibit scraping, while others may have specific guidelines. Ignoring these policies can lead to legal consequences.
Avoiding Overloading Servers
Frequent requests to a website can overload its servers, causing disruptions. Use delays between requests and respect the website's `robots.txt` file to prevent this. Here's how you can add a delay:
import time
time.sleep(2) # Delay for 2 secondsData Privacy
Ensure that the data you scrape does not violate privacy regulations, such as GDPR. Personal information should be handled with care and only collected when necessary.
Conclusion
Web scraping with MechanicalSoup offers a powerful and flexible solution for web developers, data analysts, and digital marketers. By following the steps outlined in this guide, you can efficiently extract valuable data from websites, automate repetitive tasks, and gain a competitive edge in your field.
Whether you're a seasoned professional or just starting, MechanicalSoup provides the tools you need to succeed. Remember to always consider ethical and legal aspects, follow best practices, and continuously improve your skills.
Ready to take your web scraping skills to the next level? Start experimenting with MechanicalSoup today and unlock the full potential of web data extraction. Happy scraping!