





People can easily gather and scrape information from multiple sources such as Facebook, Reddit, and Twitter. You can think of a scraper as a specialized tool that extracts data from a web page accurately and quickly. The scraping APIs help the scrapers avoid getting banned by anti-scraping techniques that the websites place. However, it is
Table of Contents
- Why Do You Need To Scrape Reddit?
- Challenges of Scraping Reddit
- How To Scrape Reddit Using Python Create Reddit API AccountImport Packages and ModulesGetting Reddit and subreddit instancesAccess The ThreadsParse and Download the DataExport CSV
- Create Reddit API Account
- Import Packages and Modules
- Getting Reddit and subreddit instances
- Access The Threads
- Parse and Download the Data
- Export CSV
- Best Reddit Proxies of 2021 SmartproxyStormproxyProxyScrapeHighproxiesInstantproxies
- Smartproxy
- Stormproxy
- ProxyScrape
- Highproxies
- Instantproxies
- Why Use Reddit Proxies?
- Alternative Solutions to Scrape Reddit ScrapestromApify’s Reddit Scraper
- Scrapestrom
- Apify’s Reddit Scraper
- Conclusion
People can easily gather and scrape information from multiple sources such as Facebook, Reddit, and Twitter. You can think of a scraper as a specialized tool that extracts data from a web page accurately and quickly. The scraping APIs help the scrapers avoid getting banned by anti-scraping techniques that the websites place. However, it is expensive to use APIs as compared to a proxy tool managed by yourself.
Have you used Reddit? If you are a social researcher and spend a lot of time online, chances are you’ve heard of Reddit. Reddit bills itself as the “front page of the Internet.” It is an online discussion forum where people share content and news or comment on other people’s posts. So, it is an incredible source of data for Internet marketers and social researchers.
Reddit has an API called the Python Reddit API Wrapper, shortened for PRAW, to crawl data. In this blog, I will be showing you steps on how to scrape Reddit using python. But before that, you need to know why you have to scrape Reddit.
Why Do You Need To Scrape Reddit?
If we talk about the design of Reddit, then it is broken into several communities known as “subreddits.” You can find any subreddit of your topic of interest on the Internet. The social researchers run analysis, make inferences, and implement actionable plans when they extract Reddit discussions for a particular topic.
You can scrape a lot of data points from Reddit, such as:
- Links
- Comments
- Images
- List of subreddits
- Submissions for each subreddit
- Usernames
- Upvotes
- Downvotes
You can scrape any information from Reddit relevant to your business because of the following needs:
- To build NLP applications
- To track customer sentiments
- To stay on top of market trends
- For consumer research
- To monitor the impact of your marketing campaigns

For instance,
- A fashion brand needs to scrape all comment texts, titles, links, images, and captions in fashion subreddits for: Devising the right pricing strategyIdentifying colour trendsDiscovering pain-points of fashionistas with various brands
- Devising the right pricing strategy
- Identifying colour trends
- Discovering pain-points of fashionistas with various brands
- Journalism and news players have to scrape author posts with blog links to train machine learning algorithms for auto text summarization.
- Investing and trading firms have to scrape “stock market” related subreddits to devise an investing plan by interpreting which stocks are being discussed.
Challenges of Scraping Reddit
Reddit scraping uses web scrapers (computer programs) to extract publicly available data from the Reddit website. You need to use the Reddit scrapers because of the limitations you are bound to face when using the official Reddit API. However, if you use the web scraper that does not use the Reddit API to extract data from Reddit, you will violate the Reddit terms of use. But it does not mean that web scraping is illegal.
To have a hitch-free scraping session, you will have to evade the anti-scraping systems put in place by Reddit. The most common anti-scraping techniques used by Reddit are:
- IP tracking
- Captchas
You can solve the problem of IP tracking with the help of proxies and IP rotation. On the other hand, you can solve the problem of Captchas by using Captcha solves such as 2Captcha.

How To Scrape Reddit Using Python
There are five ways to scrape Reddit, and they are:
- Manual Scraping – It is the easiest but least efficient method in terms of speed and cost. However, it yields data with high consistency.
- Using Reddit API – You need basic coding skills to scrape Reddit using Reddit API. It provides the data but limits the number of posts in any Reddit thread to 1000.
- Sugar-Coated third-party APIs – It is an effective and scalable approach, but it is not cost-efficient.
- Web Scraping tools – These tools are scalable and only require basic know-how of using a mouse.
- Custom Scraping scripts – They are highly customizable and scalable but require a high programming caliber.
Let’s see how we can scrape Reddit using the Reddit API with the help of the following steps.
Create Reddit API Account
You need to create a Reddit account before moving forward. To use PRAW, you must register for the Reddit API by following this link.
Import Packages and Modules
First, we will import Pandas built-in modules i-e., datetime, and two third-party modules, PRAW and Pandas, as shown below:
import praw
import pandas as pd
import datetime as dtGetting Reddit and subreddit instances
You can access the Reddit data using Praw, which stands for Python Reddit API Wrapper. First, you need to connect to Reddit by calling the praw.Reddit function and storing it in a variable. Afterward, you have to pass the following arguments to the function.
reddit = praw.Reddit(client_id='PERSONAL_USE_SCRIPT_14_CHARS', \
client_secret='SECRET_KEY_27_CHARS ', \
user_agent='YOUR_APP_NAME', \
username='YOUR_REDDIT_USER_NAME', \
password='YOUR_REDDIT_LOGIN_PASSWORD')Now, you can get the subreddit of your choice. So, call the .subreddit instance from reddit (variable), and pass the name of the subreddit you want to access. For example, you can use the r/Nootropics subreddit.
subreddit = reddit.subreddit('Nootropics')Access The Threads
Each subreddit has the below five different ways to organize the topics created by Redditors:
- .new
- .hot
- .controversial
- .gilded
- .top
You can grab the most up-voted topics as:
top_subreddit = subreddit.top()You will get a list-like object having the top 100 submissions in r/Nootropics. However, Reddit’s request limit is 1000, so you can control the sample size by passing a limit to .top as:
top_subreddit = subreddit.top(limit=600)Parse and Download the Data
You can scrape any data you want. However, we will be scraping the below information about the topics:
- id
- title
- score
- date of creation
- body text
We will do this by storing our data in a dictionary and then using a for loop as shown below.
topics_dict = { "title":[], \
"score":[], \
"id":[], "url":[], \
"created": [], \
"body":[]}Now, we can scrape the data from the Reddit API. We will append the information to our dictionary by iterating through our top_subreddit object.
for submission in top_subreddit:
topics_dict["id"].append(submission.id)
topics_dict["title"].append(submission.title)
topics_dict["score"].append(submission.score)
topics_dict["created"].append(submission.created)
topics_dict["body"].append(submission.selftext)Now, we put our data into Pandas Dataframes as Python dictionaries are not easy to read.
topics_data = pd.DataFrame(topics_dict)Export CSV
It is very easy to create data files in various formats in Pandas, so we use the following lines of code to export our data to a CSV file.
topics_data.to_csv('FILENAME.csv', index=False)Best Reddit Proxies of 2021
You know that Reddit is not much of a strict website when it comes to proxy usage restrictions. But you can be caught and penalized if you automate your actions on Reddit without using proxies.
So, let’s look at some of the best proxies for Reddit that fall into two categories:
Residential Proxies – These are the IP addresses that the Internet Service Provider (ISP) assigns to a device in a particular physical location. These proxies reveal the device’s actual location that the user uses to log in to a website.
Datacenter proxies – These are various IP addresses that do not originate from any Internet Service Provider. We acquire them from a cloud service provider.
Following are some of the top residential and datacenter proxies for Reddit.
Smartproxy
Smartproxy is one of the top premium residential proxy providers as it is effective for Reddit automation. It has an extensive IP pool and provides access to all IPs once you subscribe to its service.

Stormproxy
The pricing and unlimited bandwidth of Stormproxies make them a good choice. They are affordable and cheap to use. They have proxies for various use cases and provide the best residential proxies for Reddit automation.

ProxyScrape
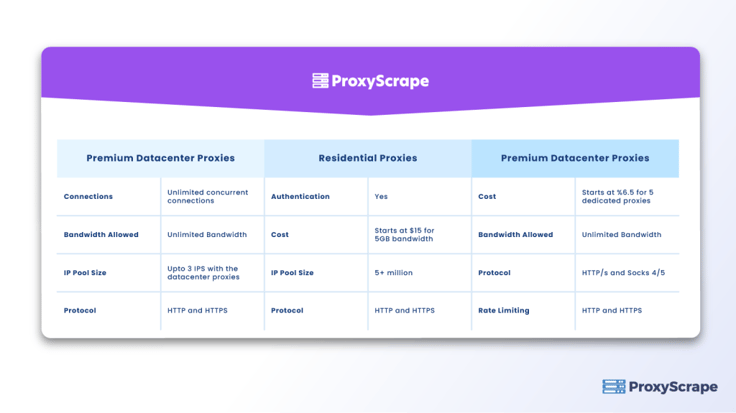
ProxyScrape is one of the popular proxy service providers that focuses on offering proxies for scraping. It also offers dedicated datacenter proxies along with the shared datacenter proxies. It has over 40k datacenter proxies that you can use to scrape data from websites on the Internet.
ProxyScrape provides three types of services to its users i-e.,
Highproxies
Highproxies work with Reddit and have the following categories of proxies:
- Shared proxies
- Private proxies
- Classified sites proxies
- Ticketing proxies
- Media proxies

Instantproxies
You can also use Instantproxies for Reddit automation as they are very secure, reliable, fast, and have an uptime of about 99.9 percent. They are the cheapest of all datacenter proxies.

Why Use Reddit Proxies?
You need proxies when you are working with some automatic tools on Reddit. It’s because Reddit is a very sensitive website that easily detects automatic actions and blocks your IP from accessing the platform. So, if you are automating some of the tasks like votes, posts, joining/unjoining groups, and managing more than one account, you definitely need to use proxies to avoid bad outcomes.
Alternative Solutions to Scrape Reddit
You can go for manual scraping if your Reddit scraping requirements are small. But if the requirements get large, you have to leverage automated scraping methodologies such as web scraping tools and custom scripts. The web scrapers prove to be cost and resource-efficient when your daily scraping requirements are within a few million posts.
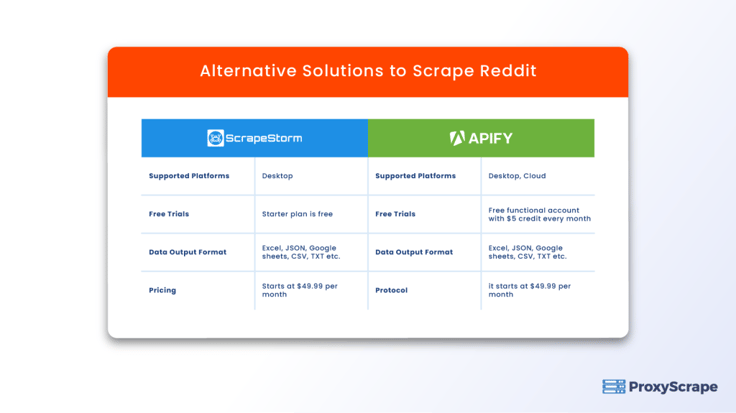
So, let’s look at some of the best Reddit scrapers as the best solution to scrape large amounts of Reddit data.
Scrapestrom
Scrapestorm is one of the best scraping tools available in the market as it works pretty great when it comes to scraping Reddit. It makes use of artificial intelligence to identify the key data points on the webpage automatically.
Apify’s Reddit Scraper
Apify’s Reddit scraper makes it easy for you to extract data without using the Reddit API. It means that you don’t need a developer API token and authorization from Reddit to download the data for commercial use. You can also optimize your scraping by using the integrated proxy service of the Apify platform.
Conclusion
We discussed five ways to scrape Reddit data, and the easiest one is to use Reddit API because it only requires basic coding skills. PRAW is a Python wrapper for the Reddit API that enables you to use a Reddit API with a clean Python interface. But when you have large Reddit scraping requirements, you can extract publicly available data from the Reddit website with the help of Reddit scrapers. To automate your actions on the Reddit website, you need to use a datacenter or residential proxies.