





Web scraping has become a vital skill for Python developers, data analysts, and anyone working with datasets. When it comes to structured and rich data, tables found on websites are often goldmines of information. Whether you’re scouring the web for product catalogs, sports statistics, or financial data, the ability to extract and save table data using Python is an invaluable tool.
This practical guide takes you step by step through the process of scraping tables from websites using Python. By the end, you’ll know how to use popular libraries like requests, Beautiful Soup, and even pandas to access table data and store it in reusable formats like CSV files.
Prerequisites
Before we jump into the technical details, here’s what you’ll need to follow along:
- Ensure Python is installed on your system. You can download the latest version here.
- Required Libraries:
- requests—To fetch the HTML content from websites. It’s a popular package for sending HTTP requests in Python.
- Beautiful Soup—A powerful library for parsing HTML and XML documents. We’ll use it to extract specific elements from our web page.
- pandas—The go-to library for data manipulation and analysis in Python. This will be our final destination where we store the extracted table data.
We will use the pip command to install the required libraries. Simply run the following command in your terminal to complete the installation:
pip install requests beautifulsoup4 pandasStep-by-Step Guide to Scraping Tables
Step 1: Understanding the Website Structure
The first step in any web scraping project is to analyze the structure of the target website. In this example, we'll be scraping data from a sample website that features a table displaying the standings for hockey teams. Below is a preview of the table:
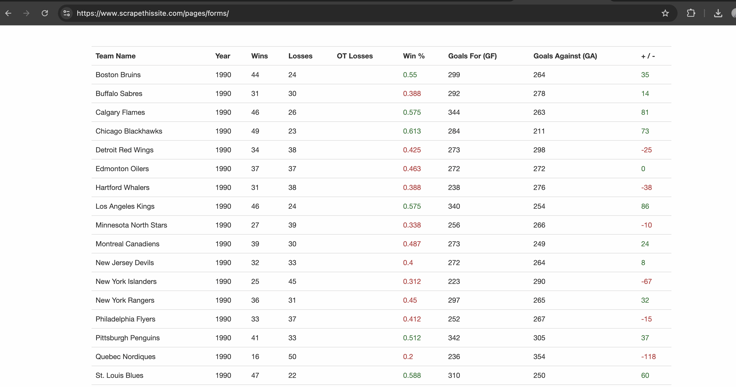
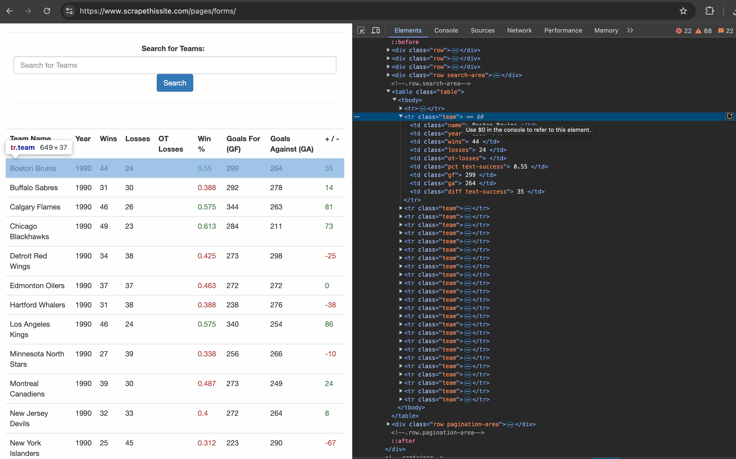
Here’s how this table appears within the HTML structure.
Step 2: Sending an HTTP Request
The first step is fetching the webpage you want to scrape. We’ll use the requests library to send an HTTP request and retrieve the HTML content from the dummy website that we are using to get the table content
url = "https://www.scrapethissite.com/pages/forms/"
response = requests.get(url)
if response.status_code == 200:
print("Page fetched successfully!")
html_content = response.text
else:
print(f"Failed to fetch the page. Status code: {response.status_code}")
exit()Step 3: Extracting data from Table
In HTML, a table is a structured way to present data in rows and columns, just like in a spreadsheet. Tables are created using the <table> tag, and their content is divided into rows (<tr>) and cells (<td> for data cells or <th> for header cells). Here's a quick breakdown of how a table's structure works:
- Table: Enclosed within
<table>tags, it acts as the container for all rows and cells. - Rows: Each
<tr>(table row) represents a horizontal slice of the table. - Cells: Inside each row,
<td>tags hold individual data values (or<th>tags for headers). - Attributes: Tables often have classes, IDs, or other attributes to style or identify them.
For example, in this script, we locate the <table> tag with a specific class (class="table") and extract its rows and cells using Beautiful Soup. This allows us to pull out the data systematically and prepare it for analysis or saving.
soup = BeautifulSoup(html_content, "html.parser")
table = soup.find("table", {"class": "table"})
if not table:
print("No table found on the page!")
exit()Step 4: Saving Data to a CSV File
In this step, we’ll save the extracted table data into a CSV file for future use and also display it as a pandas DataFrame so you can see how the data is structured. Saving the data as a CSV allows you to analyze it later in tools like Excel, Google Sheets, or Python itself.
headers = [header.text.strip() for header in table.find_all("th")]
rows = []
for row in table.find_all("tr", class_="team"):
cells = [cell.text.strip() for cell in row.find_all("td")]
rows.append(cells)
df = pd.DataFrame(rows, columns=headers)
csv_filename = "scraped_table_data_pandas.csv"
df.to_csv(csv_filename, index=False, encoding="utf-8")
print(f"Data saved to {csv_filename}") When you run this code, pandas will create a file named scraped_table_data.csv in your working directory, and the extracted data will be printed in the console as follows:
Team Name Year Wins Losses OT Losses Win % Goals For (GF) Goals Against (GA) + / -
0 Boston Bruins 1990 44 24 0.55 299 264 35
1 Buffalo Sabres 1990 31 30 0.388 292 278 14
2 Calgary Flames 1990 46 26 0.575 344 263 81
3 Chicago Blackhawks 1990 49 23 0.613 284 211 73
4 Detroit Red Wings 1990 34 38 0.425 273 298 -25
Full Code: Scraping and Saving Table Data
Below is the complete Python script for scraping table data from a website, saving it to a CSV file, and displaying the extracted data. This script combines all the steps covered in this guide into a single cohesive workflow.
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = "https://www.scrapethissite.com/pages/forms/"
response = requests.get(url)
if response.status_code == 200:
print("Page fetched successfully!")
html_content = response.text
else:
print(f"Failed to fetch the page. Status code: {response.status_code}")
exit()
soup = BeautifulSoup(html_content, "html.parser")
table = soup.find("table", {"class": "table"})
if not table:
print("No table found on the page!")
exit()
headers = [header.text.strip() for header in table.find_all("th")]
rows = []
for row in table.find_all("tr", class_="team"):
cells = [cell.text.strip() for cell in row.find_all("td")]
rows.append(cells)
df = pd.DataFrame(rows, columns=headers)
csv_filename = "scraped_table_data_pandas.csv"
df.to_csv(csv_filename, index=False, encoding="utf-8")
print(df.head())
print(f"Data saved to {csv_filename}")Conclusion
This guide has walked you through the process step by step: understanding the website structure, extracting the data, and saving it for analysis. Whether you're building datasets for research, automating data collection, or simply exploring the possibilities of web scraping, mastering these techniques opens up a world of opportunities.
While scraping, you might encounter challenges like IP bans or rate limits imposed by websites. This is where proxies become crucial. Proxies allow you to:
- Bypass Rate Limits: Rotate IP addresses to avoid being blocked by websites for sending too many requests.
- Maintain Anonymity: Keep your identity hidden by masking your real IP address.
- Access Geo-Restricted Data: Use proxies with specific locations to scrape region-specific content.
ProxyScrape offers a wide range of proxies, including residential, premium, dedicated and mobile proxies, tailored for web scraping. Their reliable and scalable proxy solutions can help you handle large-scale scraping projects without interruptions, ensuring smooth and efficient data collection.